Developers
API References
Data Subject Request API
Data Subject Request API Version 1 and 2
Data Subject Request API Version 3
Platform API
Key Management
Platform API Overview
Accounts
Apps
Audiences
Calculated Attributes
Data Points
Feeds
Field Transformations
Services
Users
Workspaces
Warehouse Sync API
Warehouse Sync API Overview
Warehouse Sync API Tutorial
Warehouse Sync API Reference
Data Mapping
Warehouse Sync SQL Reference
Warehouse Sync Troubleshooting Guide
ComposeID
Warehouse Sync API v2 Migration
Audit Logs API
Bulk Profile Deletion API Reference
Custom Access Roles API
Calculated Attributes Seeding API
Data Planning API
Group Identity API Reference
Pixel Service
Profile API
Events API
mParticle JSON Schema Reference
IDSync
Client SDKs
AMP
AMP SDK
Android
Initialization
Configuration
Network Security Configuration
Event Tracking
User Attributes
IDSync
Screen Events
Commerce Events
Location Tracking
Media
Kits
Application State and Session Management
Data Privacy Controls
Error Tracking
Opt Out
Push Notifications
WebView Integration
Logger
Preventing Blocked HTTP Traffic with CNAME
Workspace Switching
Linting Data Plans
Troubleshooting the Android SDK
API Reference
Upgrade to Version 5
Cordova
Cordova Plugin
Identity
Direct Url Routing
Direct URL Routing FAQ
Web
Android
iOS
iOS
Workspace Switching
Initialization
Configuration
Event Tracking
User Attributes
IDSync
Screen Tracking
Commerce Events
Location Tracking
Media
Kits
Application State and Session Management
Data Privacy Controls
Error Tracking
Opt Out
Push Notifications
Webview Integration
Upload Frequency
App Extensions
Preventing Blocked HTTP Traffic with CNAME
Linting Data Plans
Troubleshooting iOS SDK
Social Networks
iOS 14 Guide
iOS 15 FAQ
iOS 16 FAQ
iOS 17 FAQ
iOS 18 FAQ
API Reference
Upgrade to Version 7
React Native
Getting Started
Identity
Unity
Upload Frequency
Getting Started
Opt Out
Initialize the SDK
Event Tracking
Commerce Tracking
Error Tracking
Screen Tracking
Identity
Location Tracking
Session Management
Xamarin
Getting Started
Identity
Web
Initialization
Configuration
Content Security Policy
Event Tracking
User Attributes
IDSync
Page View Tracking
Commerce Events
Location Tracking
Media
Kits
Application State and Session Management
Data Privacy Controls
Error Tracking
Opt Out
Custom Logger
Persistence
Native Web Views
Self-Hosting
Multiple Instances
Web SDK via Google Tag Manager
Preventing Blocked HTTP Traffic with CNAME
Facebook Instant Articles
Troubleshooting the Web SDK
Browser Compatibility
Linting Data Plans
API Reference
Upgrade to Version 2 of the SDK
Alexa
Server SDKs
Node SDK
Go SDK
Python SDK
Ruby SDK
Java SDK
Quickstart
Android
Overview
Step 1. Create an input
Step 2. Verify your input
Step 3. Set up your output
Step 4. Create a connection
Step 5. Verify your connection
Step 6. Track events
Step 7. Track user data
Step 8. Create a data plan
Step 9. Test your local app
Python Quick Start
Step 1. Create an input
Step 2. Create an output
Step 3. Verify output
Guides
Partners
Introduction
Outbound Integrations
Outbound Integrations
Firehose Java SDK
Inbound Integrations
Compose ID
Data Hosting Locations
Glossary
Migrate from Segment to mParticle
Migrate from Segment to mParticle
Migrate from Segment to Client-side mParticle
Migrate from Segment to Server-side mParticle
Segment-to-mParticle Migration Reference
Rules Developer Guide
The Developer's Guided Journey to mParticle
API Credential Management
Guides
Composable Audiences
Composable Audiences Overview
User Guide
User Guide Overview
Warehouse Setup
Warehouse Setup Overview
Audience Setup
Frequently Asked Questions
Customer 360
Overview
User Profiles
Overview
User Profiles
Group Identity
Overview
Create and Manage Group Definitions
Calculated Attributes
Calculated Attributes Overview
Using Calculated Attributes
Create with AI Assistance
Calculated Attributes Reference
Predictions
Predictions Overview
What's Changed in the New Predictions UI
View and Manage Predictions
Predict Future Behavior
Future Behavior Predictions Overview
Create Future Behavior Prediction
Manage Future Behavior Predictions
Create an Audience with Future Behavior Predictions
Identity
Identity Dashboard
Identity Logs
Getting Started
Create an Input
Start capturing data
Connect an Event Output
Create an Audience
Connect an Audience Output
Transform and Enhance Your Data
Platform Guide
Billing
Usage and Billing Report
The New mParticle Experience
The new mParticle Experience
The Overview Map
Observability
Observability Overview
Observability User Guide
Observability Troubleshooting Examples
Observability Span Glossary
Platform Settings
Key Management
Audit Logs
Platform Configuration
Event Forwarding
Event Match Quality Dashboard
Notifications
System Alerts
Trends
Introduction
Data Retention
Data Catalog
Connections
Activity
Data Plans
Live Stream
Filters
Rules
Blocked Data Backfill Guide
Tiered Events
mParticle Users and Roles
Analytics Free Trial
Troubleshooting mParticle
Usage metering for value-based pricing (VBP)
IDSync
IDSync Overview
Use Cases for IDSync
Components of IDSync
Store and Organize User Data
Identify Users
Default IDSync Configuration
Profile Conversion Strategy
Profile Link Strategy
Profile Isolation Strategy
Best Match Strategy
Aliasing
Segmentation
Audiences
Audiences Overview
Create an Audience
Connect an Audience
Manage Audiences
Audience Sharing
Audience Expansion (Early Access)
Match Boost
FAQ
Inclusive & Exclusive Audiences (Early Access)
Inclusive & Exclusive Audiences Overview
Using Logic Blocks in Audiences
Combining Inclusive and Exclusive Audiences
Inclusive & Exclusive Audiences FAQ
Classic Audiences
Standard Audiences (Legacy)
Predictive Audiences
Predictive Audiences Overview
Using Predictive Audiences
New vs. Classic Experience Comparison
Analytics
Introduction
Core Analytics (Beta)
Setup
Sync and Activate Analytics User Segments in mParticle
User Segment Activation
Welcome Page Announcements
Settings
Project Settings
Roles and Teammates
Organization Settings
Global Project Filters
Portfolio Analytics
Analytics Data Manager
Analytics Data Manager Overview
Events
Event Properties
User Properties
Revenue Mapping
Export Data
UTM Guide
Analyses
Analyses Introduction
Segmentation: Basics
Getting Started
Visualization Options
For Clauses
Date Range and Time Settings
Calculator
Numerical Settings
Segmentation: Advanced
Assisted Analysis
Properties Explorer
Frequency in Segmentation
Trends in Segmentation
Did [not] Perform Clauses
Cumulative vs. Non-Cumulative Analysis in Segmentation
Total Count of vs. Users Who Performed
Save Your Segmentation Analysis
Export Results in Segmentation
Explore Users from Segmentation
Funnels: Basics
Getting Started with Funnels
Group By Settings
Conversion Window
Tracking Properties
Date Range and Time Settings
Visualization Options
Interpreting a Funnel Analysis
Funnels: Advanced
Group By
Filters
Conversion over Time
Conversion Order
Trends
Funnel Direction
Multi-path Funnels
Analyze as Cohort from Funnel
Save a Funnel Analysis
Explore Users from a Funnel
Export Results from a Funnel
Saved Analyses
Manage Analyses in Dashboards
Query Builder
Data Dictionary
Query Builder Overview
Modify Filters With And/Or Clauses
Query-time Sampling
Query Notes
Filter Where Clauses
Event vs. User Properties
Group By Clauses
Annotations
Cross-tool Compatibility
Apply All for Filter Where Clauses
Date Range and Time Settings Overview
User Attributes at Event Time
Understanding the Screen View Event
User Aliasing
Dashboards
Dashboards––Getting Started
Manage Dashboards
Dashboard Filters
Organize Dashboards
Scheduled Reports
Favorites
Time and Interval Settings in Dashboards
Query Notes in Dashboards
Analytics Resources
The Demo Environment
Keyboard Shortcuts
User Segments
Data Privacy Controls
Data Subject Requests
Default Service Limits
Feeds
Cross-Account Audience Sharing
Import Data with CSV Files
Import Data with CSV Files
CSV File Reference
Glossary
Video Index
Analytics (Deprecated)
Identity Providers
Single Sign-On (SSO)
Setup Examples
Introduction
Developer Docs
Introduction
Integrations
Introduction
Rudderstack
Google Tag Manager
Segment
Data Warehouses and Data Lakes
Advanced Data Warehouse Settings
AWS Kinesis (Snowplow)
AWS Redshift (Define Your Own Schema)
AWS S3 Integration (Define Your Own Schema)
AWS S3 (Snowplow Schema)
BigQuery (Snowplow Schema)
BigQuery Firebase Schema
BigQuery (Define Your Own Schema)
GCP BigQuery Export
Snowflake (Snowplow Schema)
Snowplow Schema Overview
Snowflake (Define Your Own Schema)
Developer Basics
Aliasing
Integrations
24i
Event
ABTasty
Audience
Aarki
Audience
Actable
Feed
AdChemix
Event
AdMedia
Audience
Adobe Marketing Cloud
Cookie Sync
Server-to-Server Events
Platform SDK Events
Adobe Audience Manager
Audience
Adobe Campaign Manager
Audience
Adobe Experience Platform
Event
Adobe Target
Audience
AdPredictive
Feed
AgilOne
Event
Amazon Kinesis
Event
Algolia
Event
Amazon Advertising
Audience
Amazon Redshift
Data Warehouse
Amazon S3
Event
Amazon SQS
Event
Amazon SNS
Event
Amobee
Audience
Anodot
Event
Antavo
Feed
Apptentive
Event
Apptimize
Event
Awin
Event
Microsoft Azure Blob Storage
Event
Bidease
Audience
Bing Ads
Event
Bluecore
Event
Bluedot
Feed
Branch S2S Event
Event
Bugsnag
Event
Cadent
Audience
Census
Feed
comScore
Event
Conversant
Event
Crossing Minds
Event
Custom Feed
Custom Feed
Databricks
Data Warehouse
Datadog
Event
Eagle Eye
Audience
Didomi
Event
Edge226
Audience
Emarsys
Audience
Epsilon
Event
Everflow
Audience
Google Analytics for Firebase
Event
Facebook Offline Conversions
Event
Flurry
Event
Flybits
Event
ForeSee
Event
FreeWheel Data Suite
Audience
Friendbuy
Event
Google Ad Manager
Audience
Google Analytics
Event
Google Analytics 4
Event
Google BigQuery
Audience
Data Warehouse
Google Enhanced Conversions
Event
Google Marketing Platform
Audience
Cookie Sync
Event
Google Marketing Platform Offline Conversions
Event
Google Tag Manager
Event
Heap
Event
Google Pub/Sub
Event
Hightouch
Feed
Herow
Feed
Hyperlocology
Event
Impact
Event
ID5
Kit
Ibotta
Event
InMarket
Audience
Inspectlet
Event
Intercom
Event
ironSource
Audience
Kafka
Event
Kissmetrics
Event
Kubit
Event
LaunchDarkly
Feed
LifeStreet
Audience
Liveramp
Audience
LiveLike
Event
Localytics
Event
MadHive
Audience
mAdme Technologies
Event
Marigold
Audience
MediaMath
Audience
Mediasmart
Audience
Apteligent
Event
Microsoft Azure Event Hubs
Event
Mintegral
Audience
Microsoft Ads
Microsoft Ads Audience Integration
Monetate
Event
Movable Ink
Event
Multiplied
Event
Movable Ink - V2
Event
Nami ML
Feed
Nanigans
Event
NCR Aloha
Event
Neura
Event
OneTrust
Event
Paytronix
Feed
Oracle BlueKai
Event
Persona.ly
Audience
Personify XP
Event
Plarin
Event
Primer
Event
Quantcast
Event
Qualtrics
Event
Rakuten
Event
Regal
Event
Reveal Mobile
Event
RevenueCat
Feed
Salesforce Mobile Push
Event
Scalarr
Event
SimpleReach
Event
Shopify
Custom Pixel
Feed
Singular-DEPRECATED
Event
Skyhook
Event
Slack
Event
Smadex
Audience
SmarterHQ
Event
Snapchat Conversions
Event
Snowflake
Audience
Data Warehouse
Snowplow
Event
Splunk MINT
Event
StartApp
Audience
Talon.One
Audience
Event
Feed
Loyalty Feed
Tapad
Audience
Tapjoy
Audience
Taplytics
Event
Taptica
Audience
Teak
Audience
The Trade Desk
Audience
Cookie Sync
Event
Ticketure
Feed
Triton Digital
Audience
Valid
Event
Vkontakte
Audience
TUNE
Event
Vungle
Audience
Webhook
Event
Webtrends
Event
Wootric
Event
White Label Loyalty
Event
Xandr
Cookie Sync
Audience
Yotpo
Feed
Yahoo (formerly Verizon Media)
Audience
Cookie Sync
YouAppi
Audience
Warehouse Sync API Tutorial
Use this tutorial to configure your first Warehouse Sync pipeline using the mParticle Postman collection, and use the data from your pipeline to create an mParticle Audience. Postman is an easy and friendly environment for both developers and non-developers to use APIs.
This tutorial is not a complete guide to all Warehouse Sync features. For a complete API reference, see the Warehouse Sync API Reference.
Prerequisites
- Install the latest version of the Postman desktop application. You can download Postman from https://www.postman.com/downloads/.
-
Fork the mParticle Warehouse Sync Postman Collection to your workspace:

A copy of the Warehouse Sync environment is included. You can download it again here.
Step 1. mParticle setup
Create Platform API credentials
You need credentials to use the Platform API to create Warehouse Sync pipelines.
To create a Platform API credential:
- After signing in to the mParticle app as a user with the Admin role, click the gear icon in the bottom left corner.

- Click Platform.
- Select the API Credentials tab.
- Click the green Add Credential button in the top right.
-
Give the credential a name, check the Platform checkbox and select Admin from the Permissions dropdown menu. Click the green Save button.
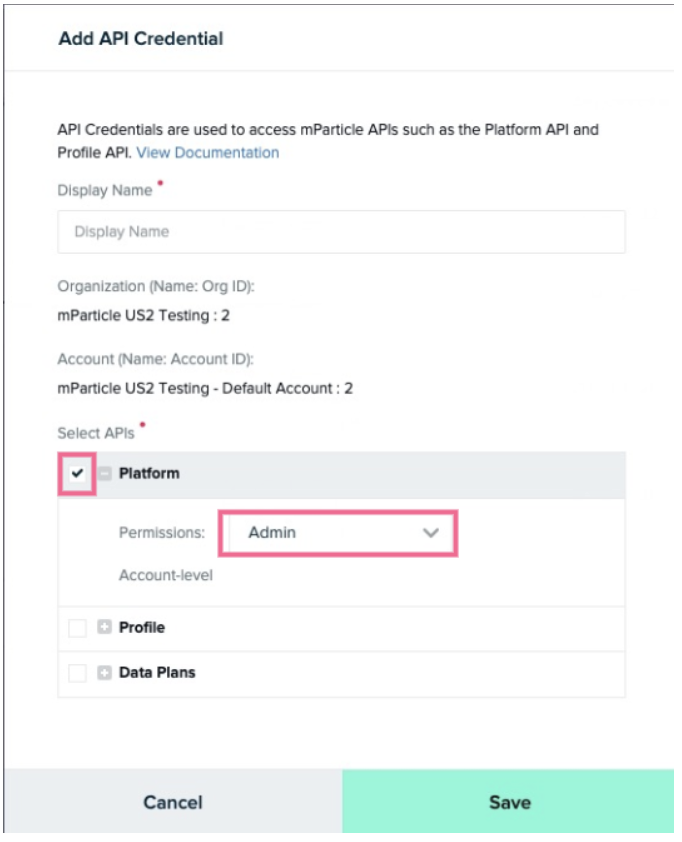
- Copy the Client ID and Client Secret values for use in a later step.
- Click Done.
Step 2. Data warehouse setup
Work with your warehouse administrator or IT team to ensure your warehouse is reachable and accessible by mParticle.
- Whitelist the mParticle IP address range so your warehouse will be able to accept inbound API requests from mParticle.
- Ask your database administrator to perform the following steps in your warehouse to create a new role that mParticle can use to access your database. Select the correct tab for your warehouse (Snowflake, Google BigQuery, Amazon Redshift, or Databricks) below.
Authentication
If you are creating a new Snowflake pipeline, you must use key pair authentication. If you have an existing Snowflake pipeline, migrate to key pair authentication.
The process for setting up key pair authentication takes two steps:
- Create a new key pair by following the instructions in Key Management.
- Assign the public key you created to your Snowflake user. You will do this when setting up Snowflake as described in the instructions below.
Migrate to key pair authentication
If you have an existing Snowflake configuration that you want to migrate to key pair authentication:
- Create a new key pair.
- From your Snowflake console, assign the public key to your Snowflake user by running the following, where
mparticle_useris replaced with the name of the user you created for your configuration andYOUR-PUBLIC-KEYis replaced with your new public key:
// If you are rolling over to a new RSA key, you can use RSA_PUBLIC_KEY_2 instead of RSA_PUBLIC_KEY
ALTER USER mparticle_user SET RSA_PUBLIC_KEY='YOUR-PUBLIC-KEY';- In mParticle, navigate to Data Platform > Setup > Inputs and select the Feeds tab.
- Under Snowflake, select the configuration you want to migrate, and click Settings.
- Remove the password you have entered under Password, and enter the Key ID for the key pair you created in mParticle under Key ID.
- Click Save.
Snowflake setup
Run the following commands from your Snowflake instance:
USE ROLE ACCOUNTADMIN;
// mParticle recommends creating a unique role for warehouse sync
CREATE ROLE IF NOT EXISTS {{role_name}};
GRANT USAGE ON WAREHOUSE {{warehouse}} TO ROLE {{role_name}};
GRANT USAGE ON DATABASE {{database}} TO ROLE {{role_name}};
GRANT USAGE ON SCHEMA {{database}}.{{schema}} TO ROLE {{role_name}};
GRANT MODIFY PROGRAMMATIC AUTHENTICATION METHODS TO ROLE {{role_name}};
// Grant SELECT privilege on any tables/views mP needs to access
GRANT SELECT ON TABLE {{database}}.{{schema}}.{{table}} TO ROLE {{role_name}};
// mParticle recommends creating a unique user for mParticle
// If you are rolling over to a new RSA key, you can use RSA_PUBLIC_KEY_2 instead of RSA_PUBLIC_KEY
// To learn more about key pair rotation, see: https://docs.snowflake.com/en/user-guide/key-pair-auth#configuring-key-pair-rotation
CREATE OR REPLACE USER {{user_name}} RSA_PUBLIC_KEY = "{{your_public_key}}"
GRANT ROLE {{role_name}} TO USER {{user_name}};
CREATE OR REPLACE STORAGE INTEGRATION {{storage_integration_name}}
WITH TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = S3
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = "arn:aws:iam::{{mp_pod_aws_account_id}}:role/ingest-pipeline-data-external-{{mp_org_id}}-{{mp_acct_id}}"
STORAGE_AWS_OBJECT_ACL = "bucket-owner-full-control"
STORAGE_ALLOWED_LOCATIONS = ("s3://{{mp_pod}}-ingest-pipeline-data/{{mp_org_id}}/{{mp_acct_id}}");
GRANT USAGE ON INTEGRATION {{storage_integration_name}} TO ROLE {{role_name}};
// Optional
CREATE OR REPLACE STAGE {{schema}}.{{external_stage_name}}
URL = "s3://{{mp_pod}}-ingest-pipeline-data/{{mp_org_id}}/{{mp_acct_id}}"
STORAGE_INTEGRATION = {{storage_integration_name}}
FILE_FORMAT = (
TYPE = json
NULL_IF = 'NULL'
TIMESTAMP_FORMAT = 'YYYY-MM-DD HH24:MI:SS.FF3TZH:TZM',
STRIP_NULL_VALUES = FALSE
)
GRANT USAGE ON STAGE {{external_stage_name}} TO ROLE {{role_name}};Where:
role_name: The ID of the role mParticle will assume while executing SQL commands on your Snowflake instance. mParticle recommends creating a unique role for warehouse sync.warehouse: The ID of the Snowflake virtual warehouse compute cluster where SQL commands will be executed.database: The ID of the database in your Snowflake instance from which you want to sync data.schema: The ID of the schema in your Snowflake instance containing the tables you want to sync data from.table: The ID of the table containing data you want to sync. Grant SELECT privileges on any tables/views mParticle needs to access.user_name: The ID of the user mParticle will log in as while executing SQL commands on your Snowflake instance. mParticle recommends creating a unique role for warehouse sync.your_public_key: the public key of the private/public key pair you created in mParticle.storage_integration_name: The ID of a Snowflake external storage integration allowing mParticle to unload data from your Snowflake instance to an S3 storage bucket.mp_pod: The mParticle region ID of your data hosting location, one ofUS1,US2,AU1, orEU1.-
mp_pod_aws_account_id: The mParticle provided ID for the data hosting location where your organization resides. Use the corresponding value for your mParticle instance:- US1:
338661164609 - US2:
386705975570 - AU1:
526464060896 - EU1:
583371261087
- US1:
mp_org_id: The mParticle provided ID of your organization where this connection will be stored. This can be found from your API client setup in step 1.mp_acct_id: The mParticle provided ID of the account where this connection will be stored. This can be found from your API client setup in step 1.external_stage_name: The ID of a Snowflake external stage used instead of explicit URLs for transfer. This is useful whenPREVENT_UNLOAD_TO_INLINE_URLis enabled.
Create a new service account for mParticle
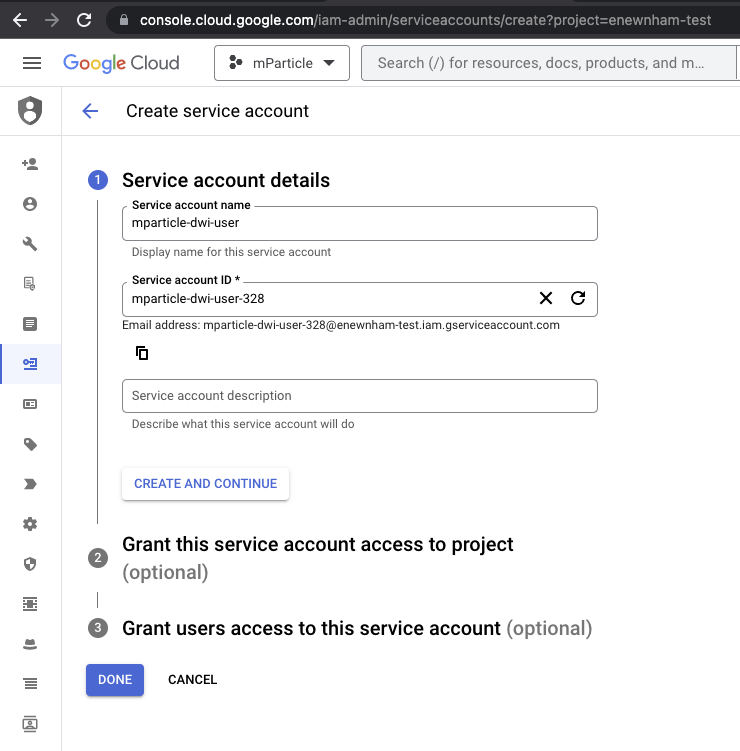
- Go to console.cloud.google.com, log in, and navigate to IAM & Admin > Service Accounts.
- Select Create Service Account.
- Enter a new identifier for mParticle in Service account ID. In the example below, the email address is the service account ID. Save this value for your Postman setup.
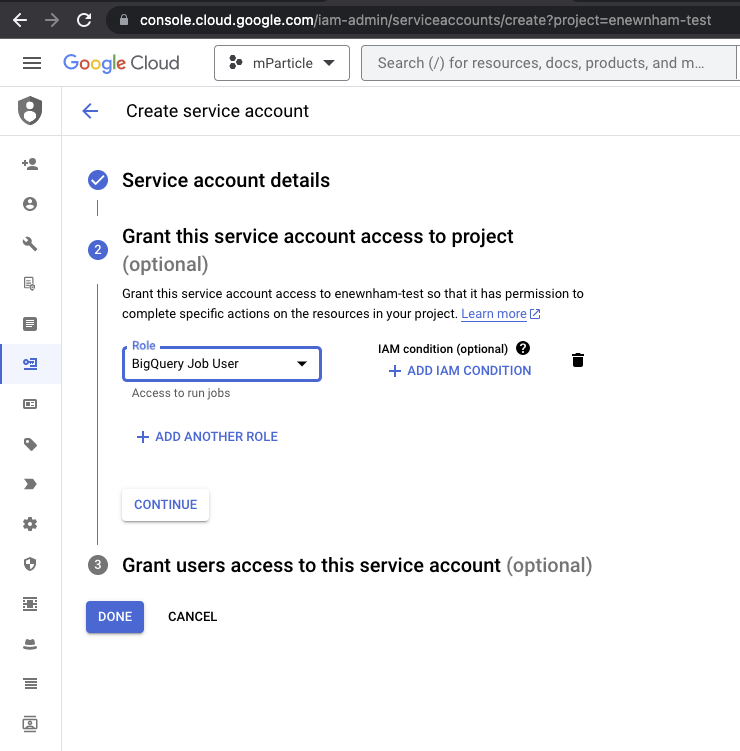
- Under Grant this service account access to project, select BigQuery Job User under the Role dropdown menu, and click DONE.
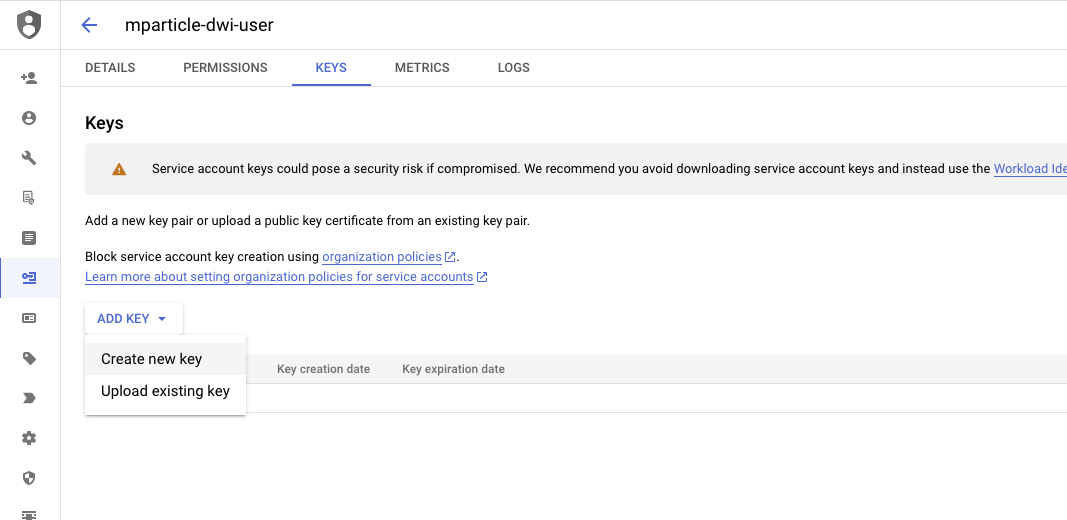
- Select your new service account and navigate to the Keys tab.
- Click ADD KEY and select Create new key. The value for
service_account_keywill be the contents of the generated JSON file. Save this value for your Postman setup.
Identify your BigQuery warehouse details
Navigate to your BigQuery instance from console.cloud.google.com.
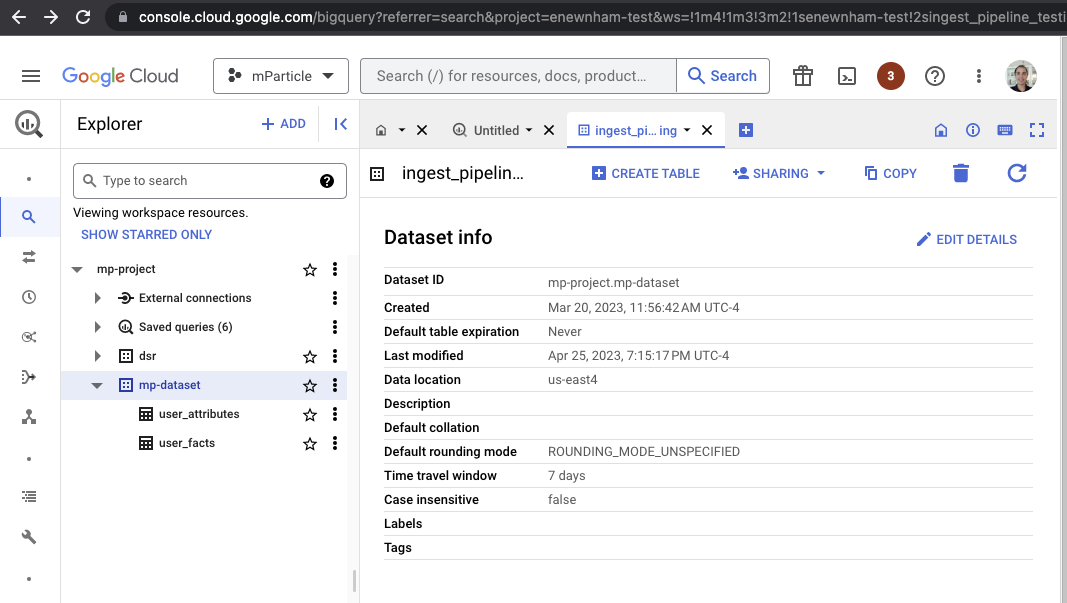
- Your
project_idis the first portion of Dataset ID (the portion before the.). In the example above, it ismp-project. - Your
dataset_idis the second portion of Dataset ID (the portion immediately after the.) In the example above, it ismp-dataset. - Your
regionis the Data location. This isus-east4in the example above.
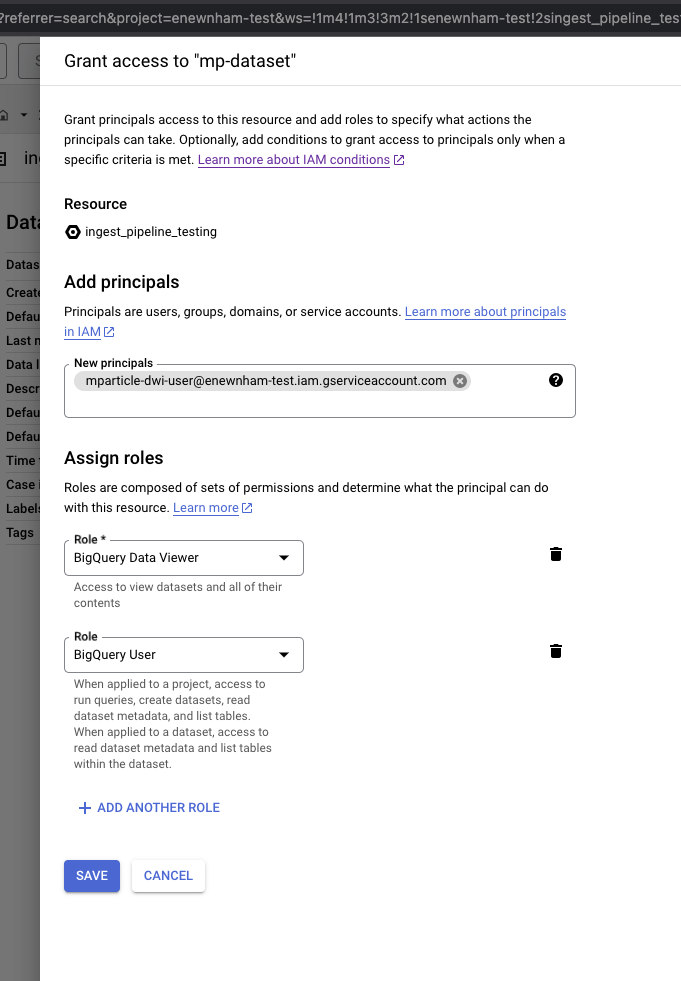
Grant access to the dataset in BigQuery
- From your BigQuery instance in console.cloud.google.com, click Sharing and select Permissions.
- Click Add Principle.
- Assign two Roles, one for BigQuery Data Viewer, and one for BigQuery User.
- Click Save.
- Navigate to your AWS Console, log in with your administrator account, and navigate to your Redshift cluster details.
- Run the following SQL statements to create a new user for mParticle, grant the necessary schema permissions to the new user, and grant the necessary access to your tables/views.
-- Create a unique user for mParticle
CREATE USER {{user_name}} WITH PASSWORD '{{unique_secure_password}}'
-- Grant schema usage permissions to the new user
GRANT USAGE ON SCHEMA {{schema_name}} TO {{user_name}}
-- Grant SELECT privilege on any tables/views mP needs to access to the new user
GRANT SELECT ON TABLE {{schema_name}}.{{table_name}} TO {{user_name}}- Navigate to the Identity And Access Management (IAM) dashboard, select Roles under the left hand nav bar, and click Create role.
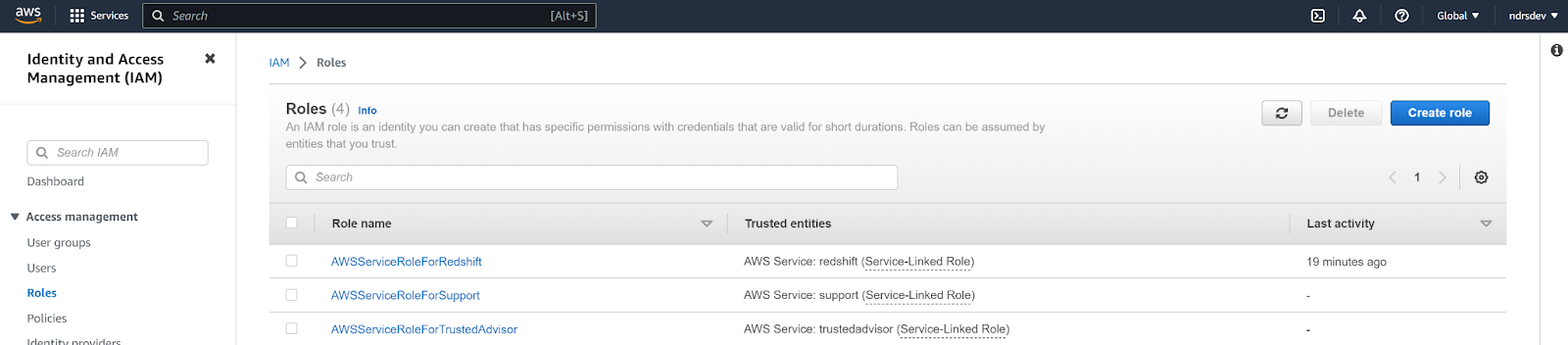
- In Step 1 Select trusted entity, click AWS service under Trusted entity
- Select Redshift from the dropdown menu titled “Use cases for other AWS services”, and select Redshift - Customizable. Click Next.

- In Step 2 Add permissions, click Create Policy.
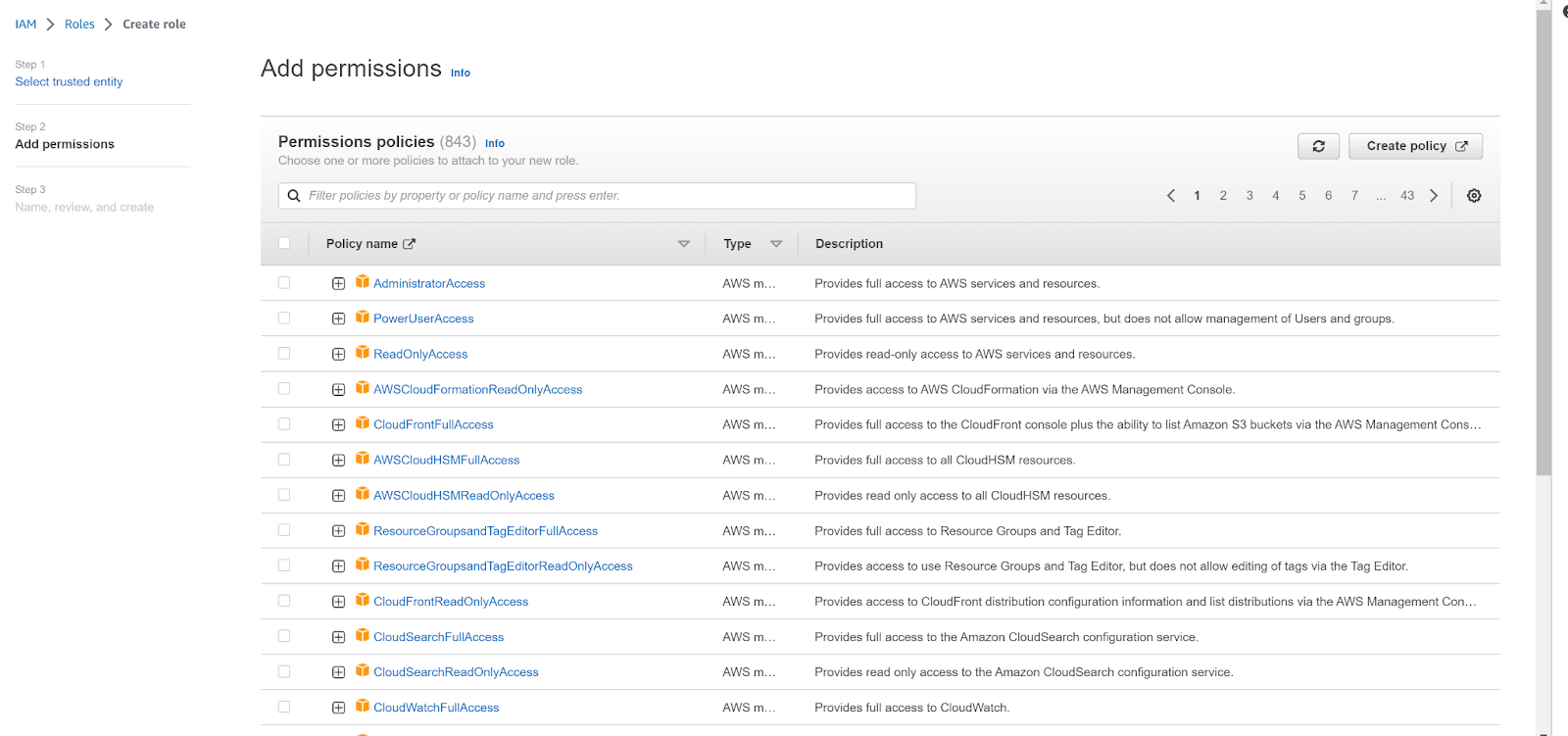
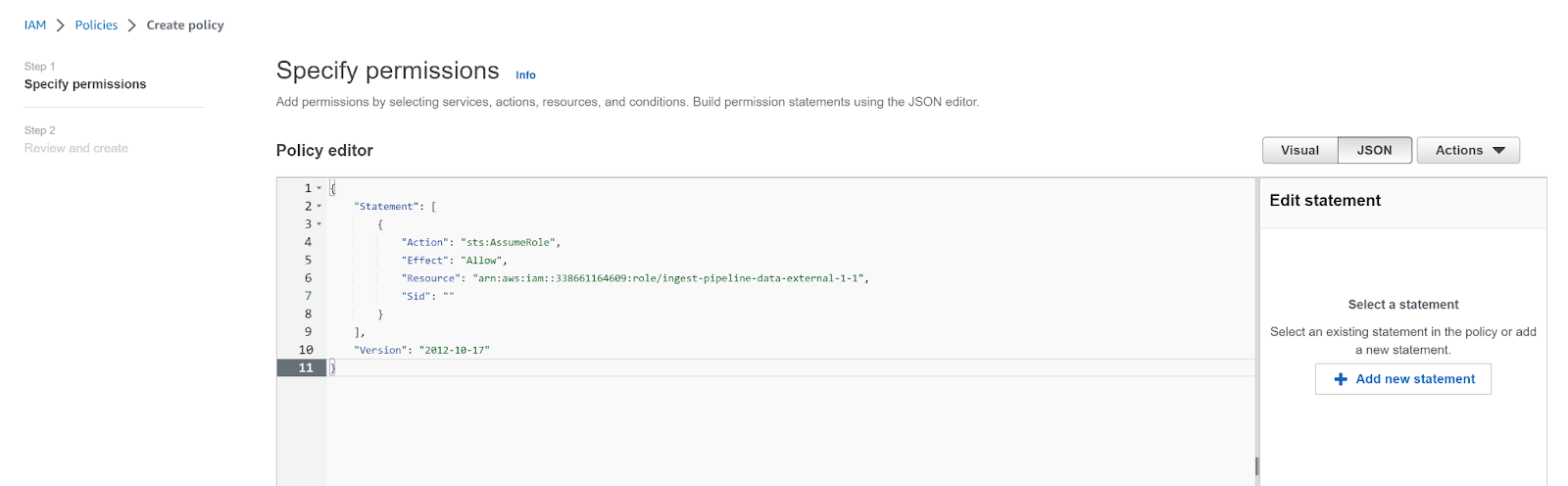
- Click JSON in the policy editor, and enter the following permissions before clicking Next.
-
Replace
{mp_pod_aws_account_id}with one of the following values according to your mParticle instance’s location:- US1 =
338661164609 - US2 =
386705975570 - AU1 =
526464060896 - EU1 =
583371261087
- US1 =
{
"Statement": [
{
"Action": "sts:AssumeRole",
"Effect": "Allow",
"Resource": "arn:aws:iam::{{mp_pod_aws_account_id}}:role/ingest-pipeline-data-external-{{mp_org_id}}-{{mp_acct_id}}",
"Sid": ""
}
],
"Version": "2012-10-17"
}
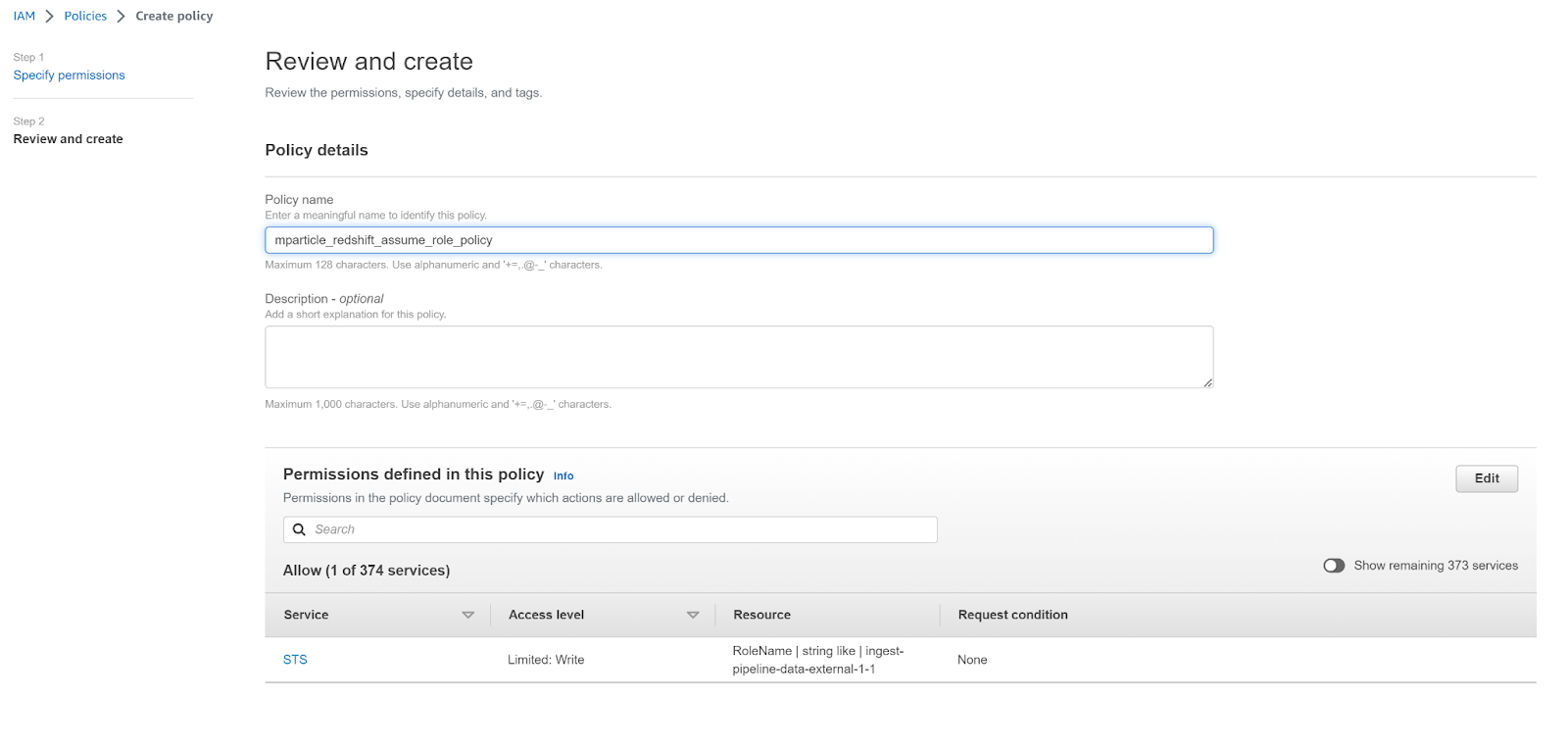
- Enter a meaningful name for your new policy, such as
mparticle_redshift_assume_role_policy, and click Create policy.
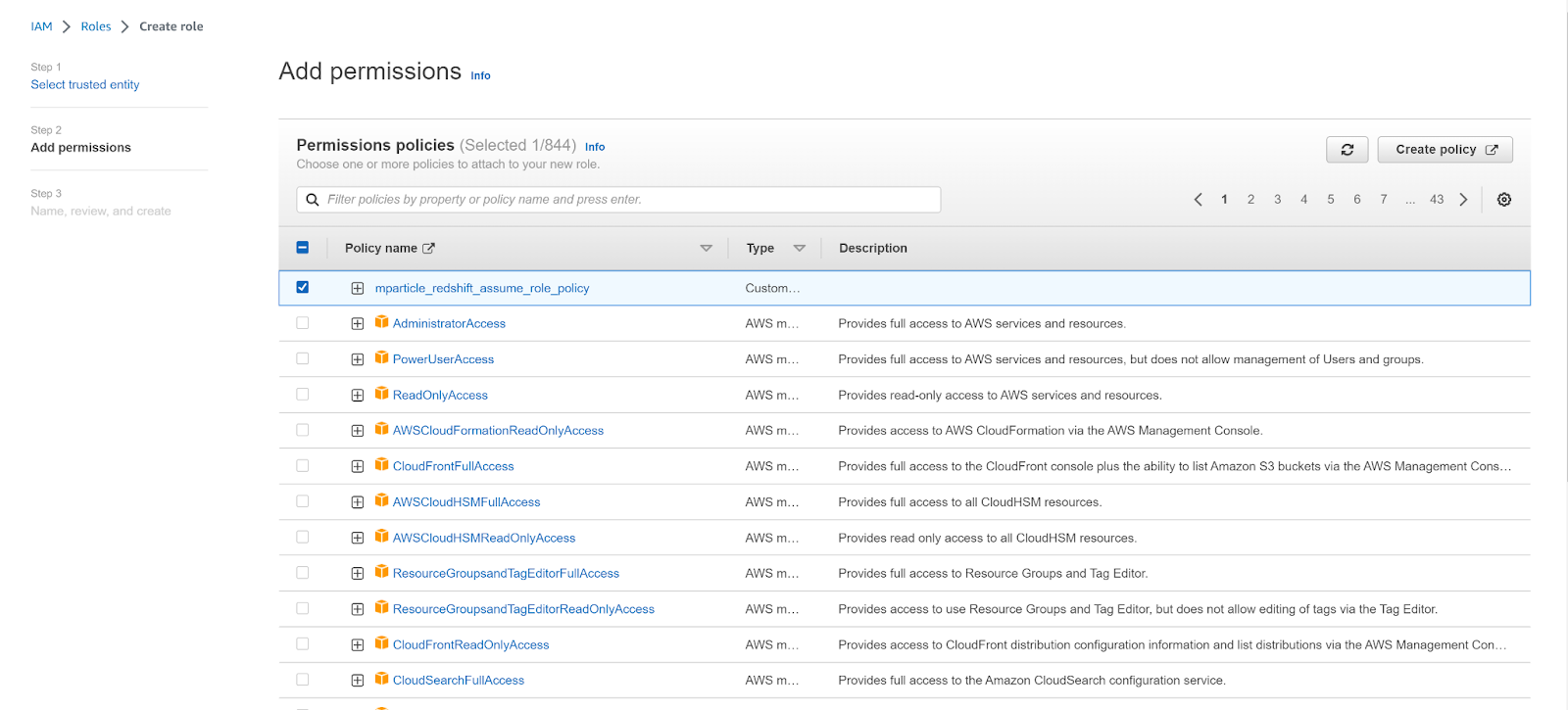
- Return to the Create role tab, click the refresh button, and select your new policy. Click Next.
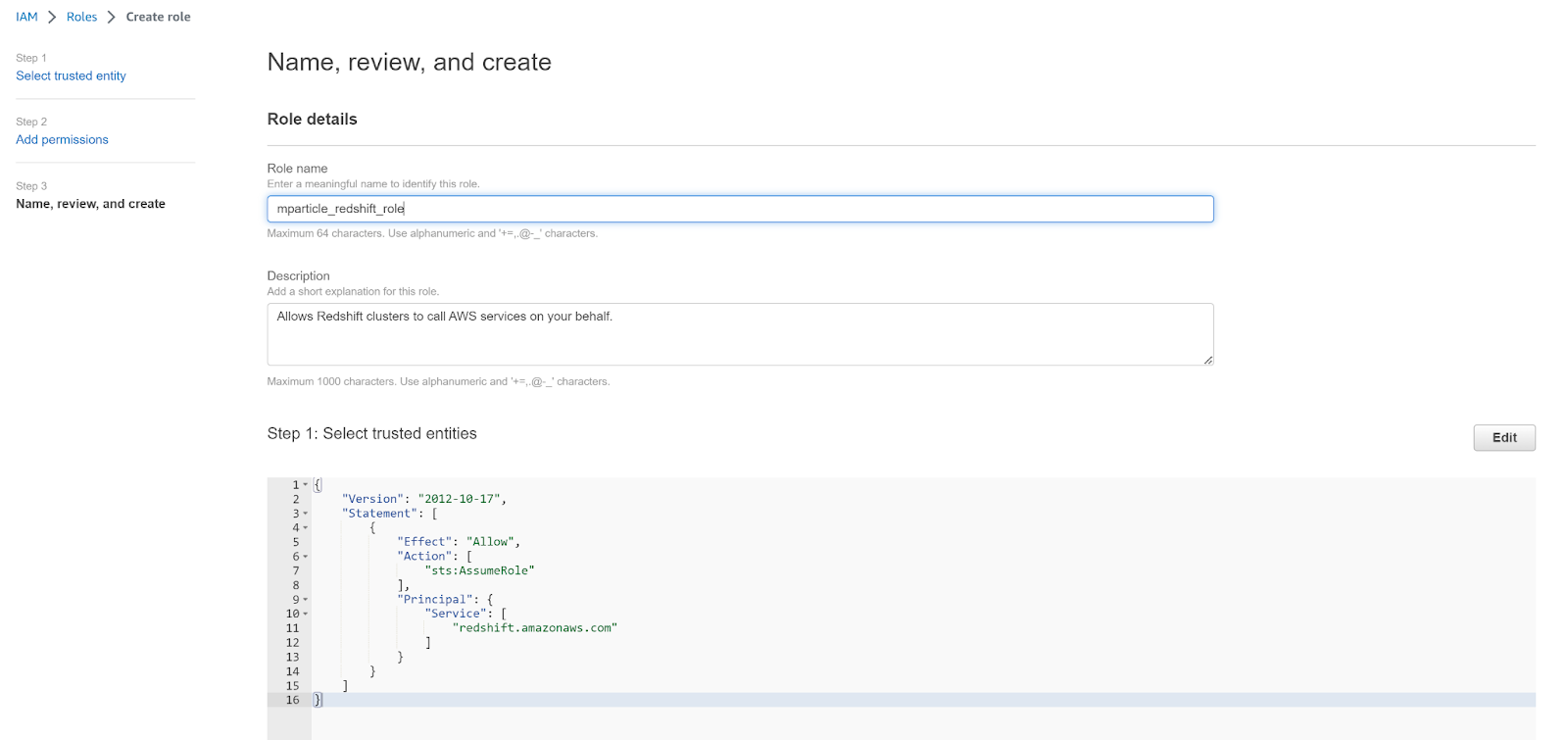
- Enter a meaningful name for your new role, such as
mparticle_redshift_role, and click Create role.
Your configuration will differ between Amazon Redshift and Amazon Redshift Serverless. To complete your configuration, follow the appropriate steps for your use case below.
Make sure to save the value of your new role’s ARN. You will need to use this when setting up Postman in the next section.
Amazon Redshift (not serverless)
- Navigate to your AWS Console, then navigate to Redshift cluster details. Select the Properties tab.
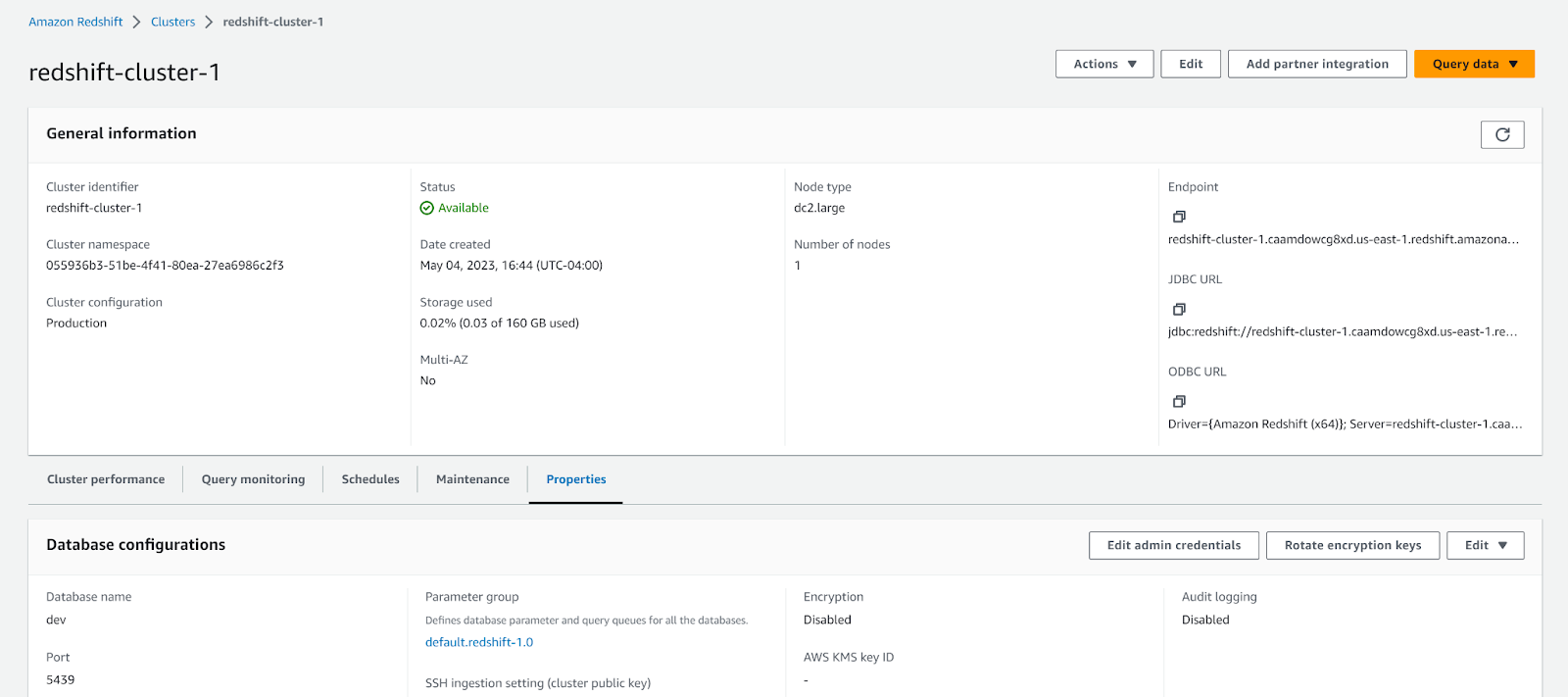
- Scroll to Associated IAM roles, and select Associate IAM Roles from the Manage IAM roles dropdown menu.
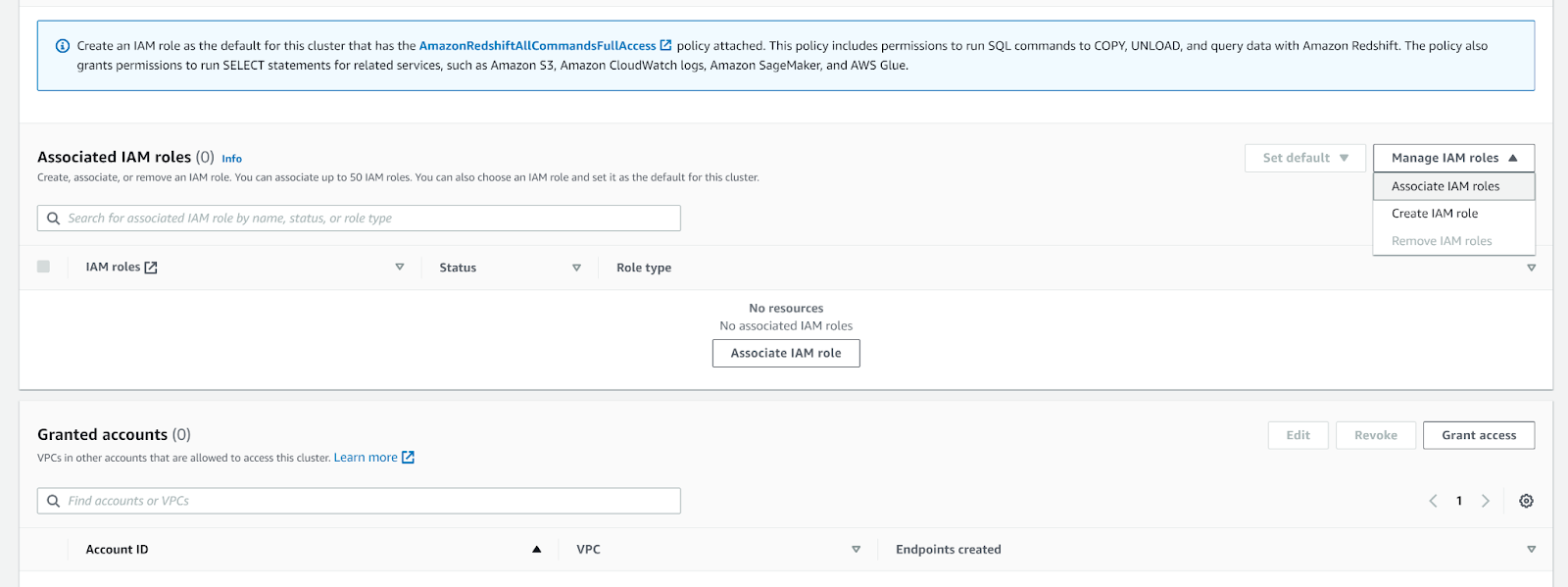
- Select the new role you just created. The name for the role in this example is
mparticle_redshift_role.
Amazon Redshift Serverless
- Navigate to your AWS Console, then navigate to your Redshift namespace configuration. Select the Security & Encryption tab, and click Manage IAM roles.
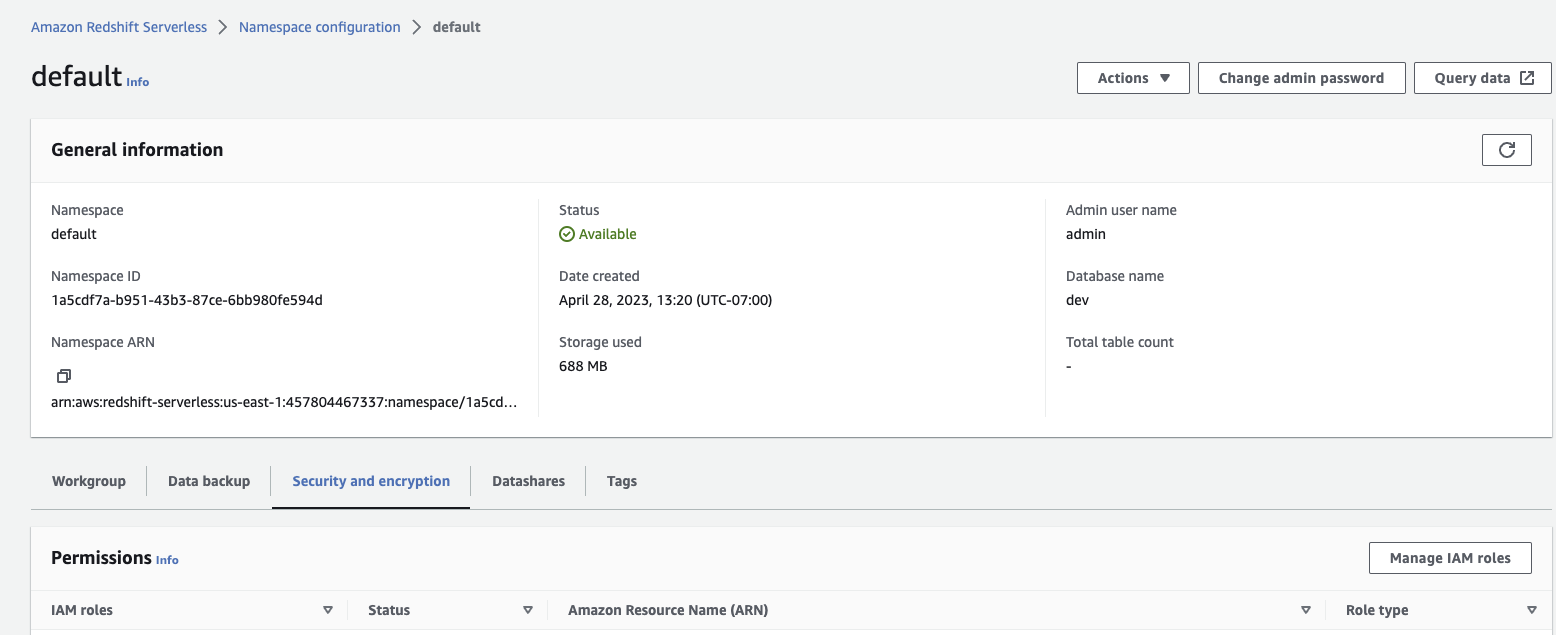
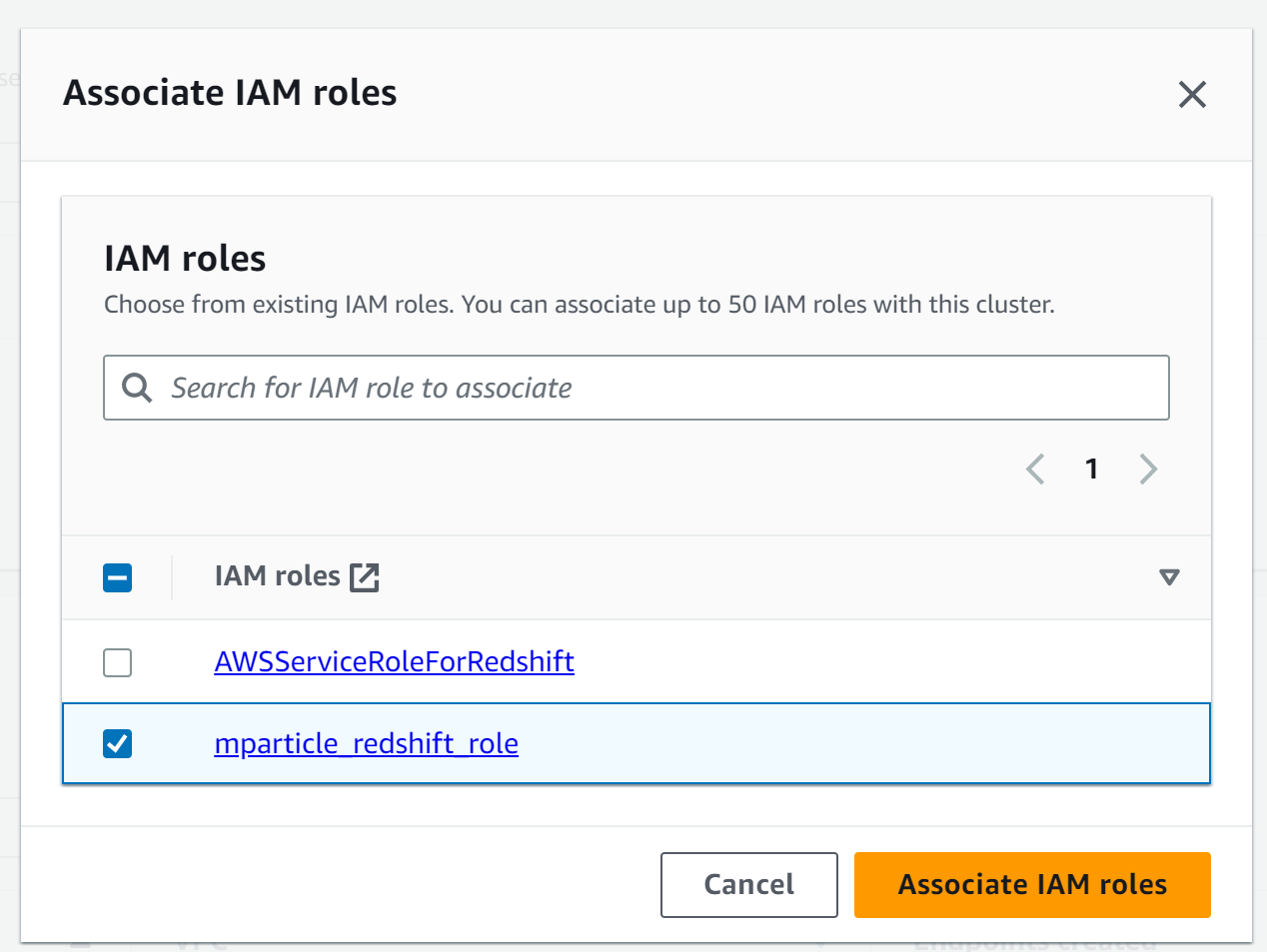
- Select Associate IAM roles from the Manage IAM roles dropdown menu.
- Select the new role you just created. The name for the role in this example is
mparticle_redshift_role.
Warehouse Sync uses the Databricks-to-Databricks Delta Sharing protocol to ingest data from Databricks into mParticle.
Complete the following steps to prepare your Databricks instance for Warehouse Sync.
1. Enable Delta Sharing
- Log into your Databricks account and navigate to the Account Admin Console. You must have Account Admin user privileges.
- Click Catalog from the left hand nav bar, and select the metastore you want to ingest data from.
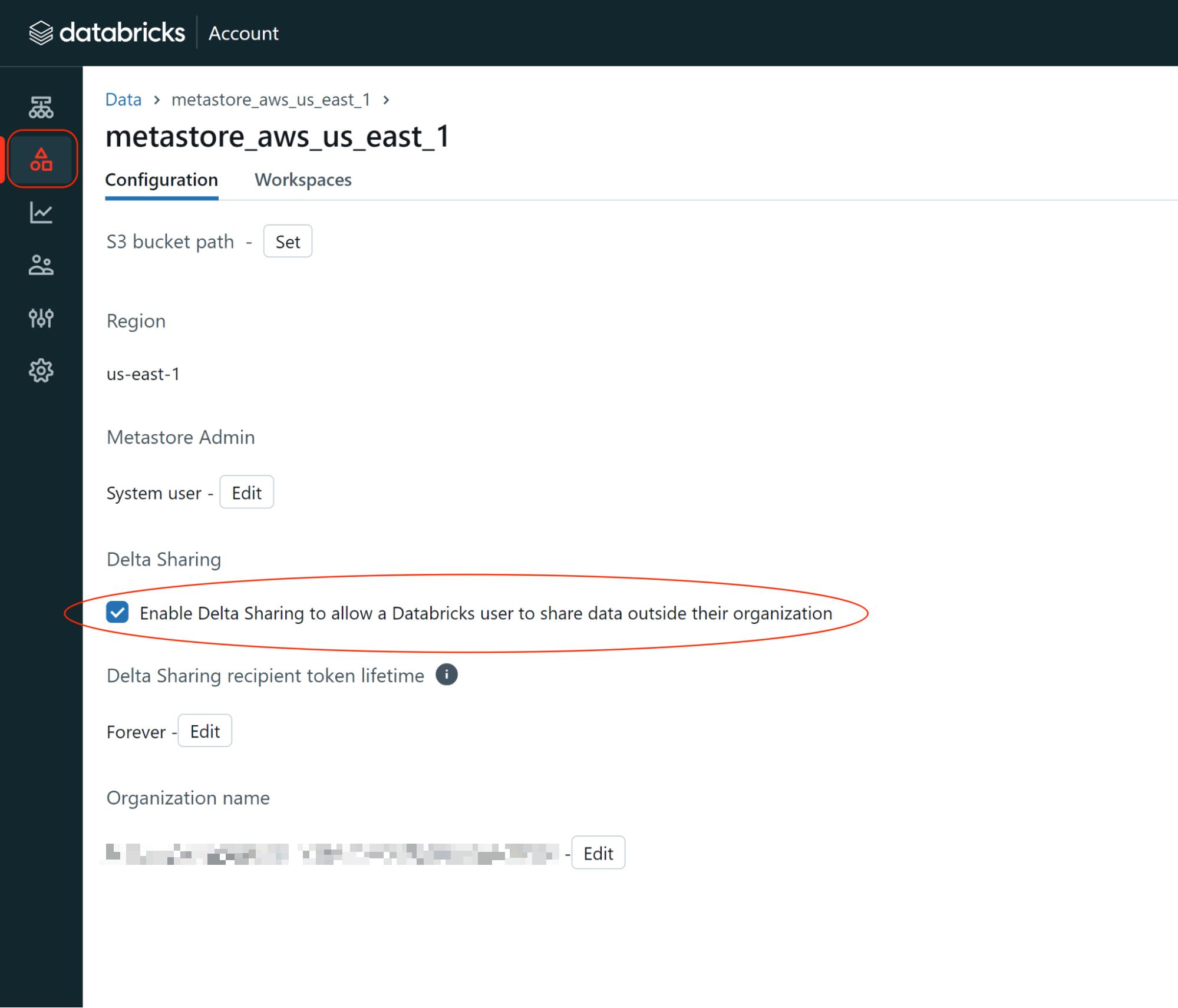
- Select the Configuration tab. Under Delta Sharing, check the box labeled “Allow Delta Sharing with parties outside your organization”.
- Find and save your Databricks provider name: the value displayed under Organization name. You will use this value for your provider name when creating the connection between the mParticle Warehouse Sync API and Databricks.
2. Configure a Delta Sharing recipient for mParticle
- From the Unity Catalog Explorer in your Databricks account, click the Delta Sharing button, and select Shared by me.
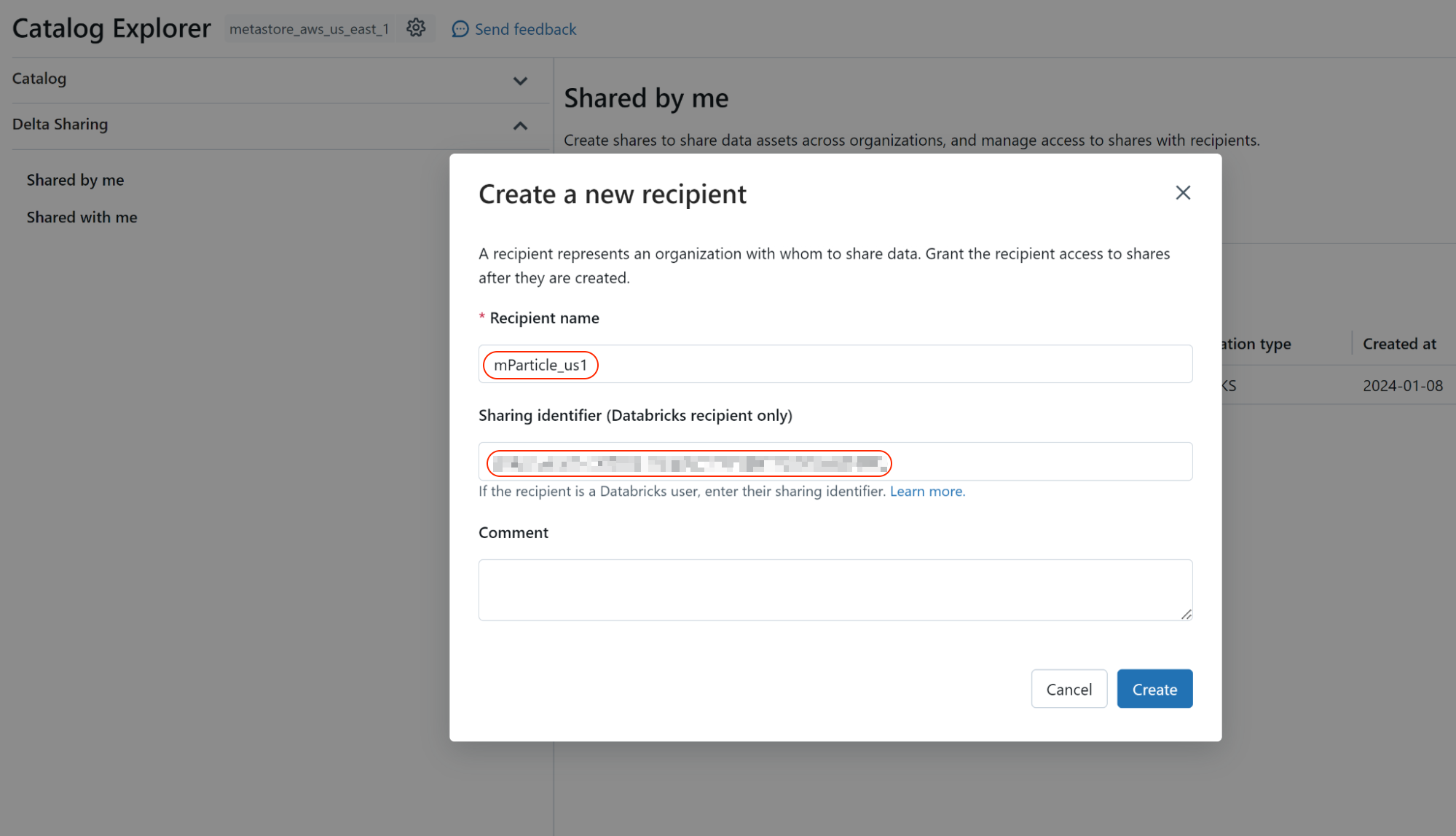
- Click New Recipient in the top right corner.
- Within the Create a new recipient window, enter
mParticle_{YOUR-DATA-POD}under Recipient name where{YOUR-DATA-POD}is eitherus1,us2,eu1, orau1depending on the location of the data pod configured for your mParticle account. -
In Sharing identifier, enter one of the following identifiers below, depending on the location of your mParticle account’s data pod:
- US1:
aws:us-east-1:e92fd7c1-5d24-4113-b83d-07e0edbb787b - US2:
aws:us-east-1:e92fd7c1-5d24-4113-b83d-07e0edbb787b - EU1:
aws:eu-central-1:2b8d9413-05fe-43ce-a570-3f6bc5fc3acf - AU1:
aws:ap-southeast-2:ac9a9fc4-22a2-40cc-a706-fef8a4cd554e
- US1:
3. Share your Databricks tables and schema with your new Delta Sharing recipient
- From the Unity Catalog Explorer in your Databricks account, click the Delta Sharing button.
- Click Share data in the top right.
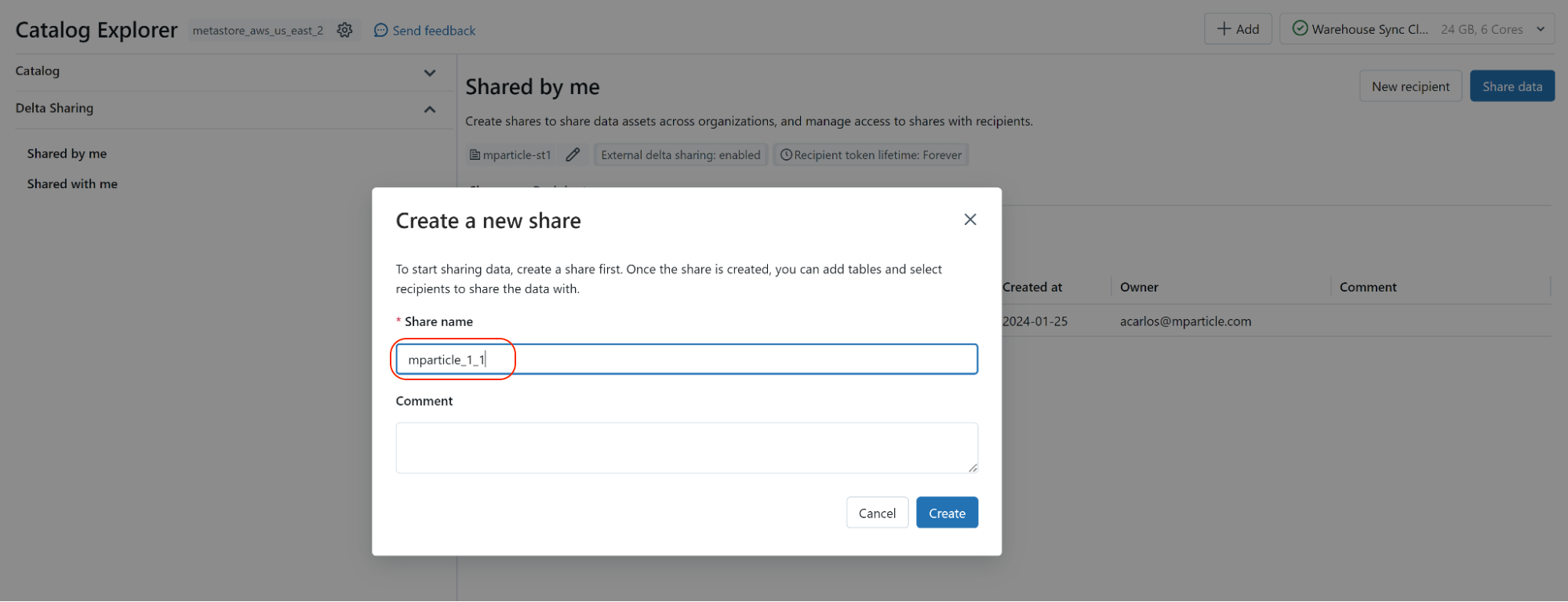
-
Within the Create share window, enter
mparticle_{YOUR-MPARTICLE-ORG-ID}_{YOUR-MPARTICLE-ACCOUNT-ID}under Share name where{YOUR-MPARTICLE-ORG-ID}and{YOUR-MPARTICLE-ACCOUNT-ID}are your mParticle Org and Account IDs.- To find your Org ID, log into the mParticle app. View the page source. For example, in Google Chrome, go to View > Developer > View Page Source. In the resulting source for the page, look for “orgId”:xxx. This number is your Org ID.
- Follow a similar process to find your Account ID (“accountId”:yyy) and Workspace ID (“workspaceId”:zzz).
- Click Save and continue at the bottom right.
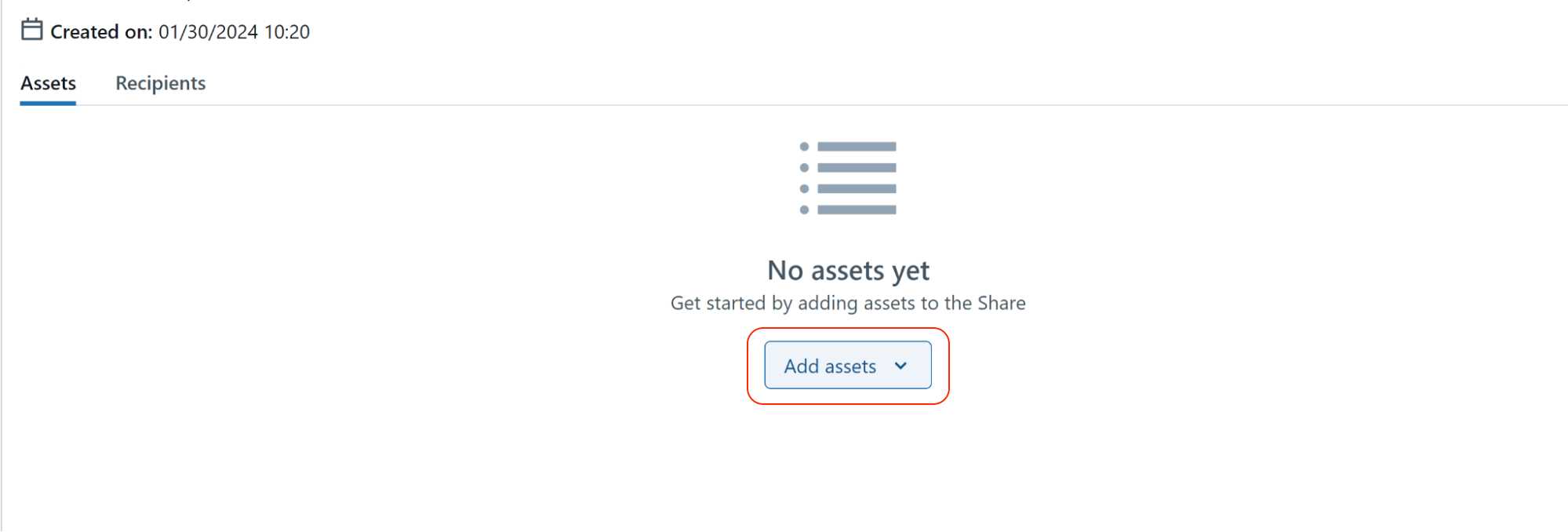
- In the Add data assets section, select the assets to add to the schemas and tables you want to send to mParticle. Make sure to remember your schema name: you will need this value when configuring your Databricks feed in mParticle.
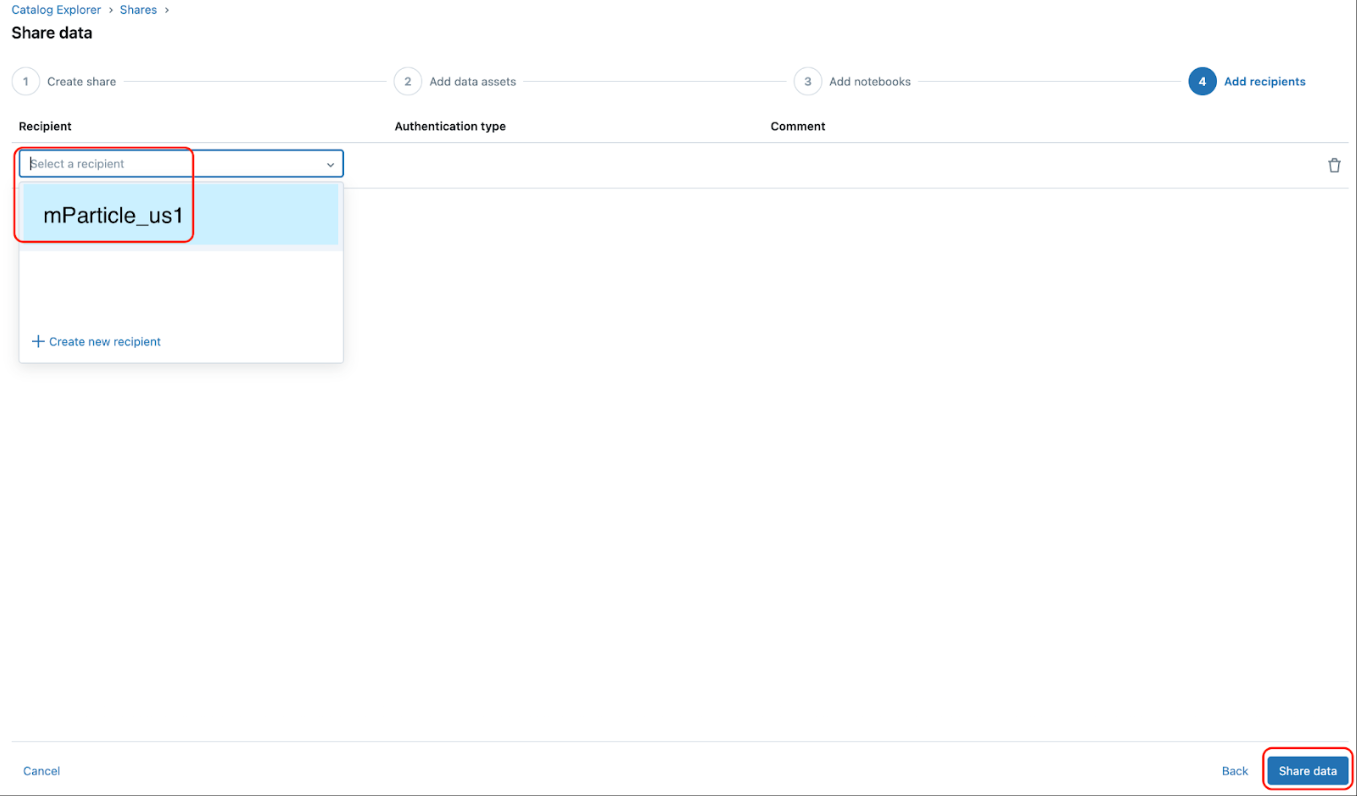
- Click Save and continue at the bottom right until you reach the Add recipients step. (You can skip the Add notebooks step.)
- In the Add recipients step, make sure to add the new mParticle recipient you created in Step 2.
- Finally, click the Share data button at the bottom right.
Unsupported data types between mParticle and Databricks
Databricks Delta Sharing does not currently support the TIMESTAMP_NTZ data type.
Other data types that are not currently supported by the Databricks integration for Warehouse Sync (for both user and events data) include:
If you are ingesting events data through Warehouse Sync, the following data types are unsupported:
While multi-dimensional, or nested, arrays are unsupported, you can still ingest simple arrays with events data.
Step 3. Postman setup
Once you have installed Postman, configure the collection environment settings and variables.
Update Postman environment settings
- Ensure you forked the mParticle Warehouse Sync API Postman Collection, as described in the Prerequisites section of this tutorial. In Postman, click the Environments tab from the left navigation menu.
-
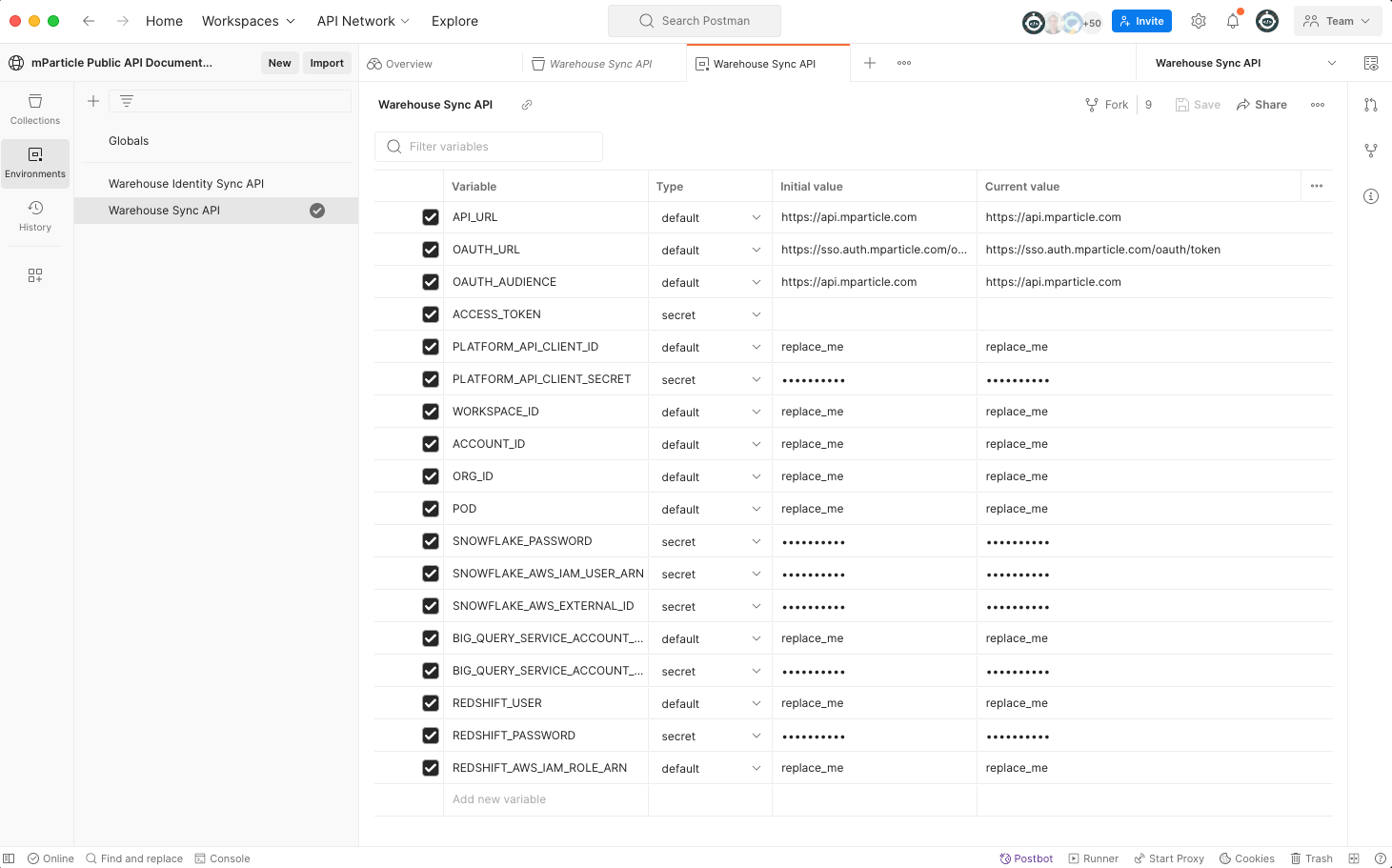
If you successfully forked the Warehouse Sync API collection, you’ll see it in the list of Environment configurations. You can rename it to something more meaningful by right-clicking on the … next to the name and choosing the Rename option.
-
Replace the the placeholders (
replace_me) with the correct values for your environment. You must update the values under column labeled Current value.- Replace
PLATFORM_API_CLIENT_IDandPLATFORM_API_CLIENT_SECRETwith your new Platform API credentials. -
Replace
WORKSPACE_ID,ACCOUNT_ID, andORG_IDwith the corresponding values for your mParticle account.- To find your Org ID, log into the mParticle app. View the page source. For example, in Google Chrome, go to View > Developer > View Page Source. In the resulting source for the page, look for “orgId”:xxx. This number is your Org ID.
- Follow a similar process to find your Account ID (“accountId”:yyy) and Workspace ID (“workspaceId”:zzz).
- Replace
PODwith the regional pod your mParticle account is deployed on. Look at the URL in your browser where you are signed into mParticle. The POD is one of the following values: US1, US2, EU1, AU1.
- Replace
-
Enter the data warehouse usernames and passwords you saved from “Step 2. Data Warehouse Setup.” according to the data warehouse you are using:
- For Snowflake, replace
SNOWFLAKE_PASSWORDandSNOWFLAKE_STORAGE_INTEGRATIONwith the values you saved in step 2. Please refer to the Snowflake documentation to determine youraccount_identifierandregion. - For BigQuery, replace
BIG_QUERY_SERVICE_ACCOUNT_IDwith the service account ID you used in BigQuery, andBIG_QUERY_SERVICE_ACCOUNT_KEYwith the key from the generated JSON file in step 2. - For Redshift, replace
REDSHIFT_USER,REDSHIFT_PASSWORD, andREDSHIFT_AWS_IAM_ROLE_ARNwith the values created in step 2.
- For Snowflake, replace
- After updating all necessary values, run COMMAND-S (or CTRL-S) to save your changes.
Update the Postman collection
- Ensure you forked the mParticle Warehouse Sync API Postman Collection as described in the Prerequisites section. In Postman, click the Collections tab on the left hand navigation.
- Once successfully forked, you’ll see the collection in the list of available collections.
- Click Warehouse Sync API, then select the Variables tab.
-
Replace
replace_meplaceholders with the values corresponding to your environment. Ensure you update the values in the Current value column.- Replace
INGEST_PIPELINE_SLUGandINGEST_PIPELINE_NAMEwith the slug and name you want to use to identify your new pipeline. -
Replace
SQL_QUERYwith the database SQL query mParticle will use to retrieve data from your warehouse. SQL is a powerful language and you can use advanced expressions to filter, aggregate, join, etc. your data. Work with your database administrator if you need help crafting the right SQL query:- Your query can contain a timestamp column that mParticle will use to keep track of which rows need to be loaded.
- Your query should contain one or more user identity columns that mParticle will use to perform identity resolution to ensure that data ends up on the correct user profile.
-
As part of the SQL query, you must specify how columns in the query will map to attributes on a user’s profile. You do this by using column aliasing in SQL. For example, in the following query, the column
cidin Snowflake is being mapped to the mParticle attributecustomer_id.
If you don’t provide an alias, mParticle will use the name of the column in your database. If an attribute of this name does not already exist on the user’s profile, mParticle will create a new attribute with this name.
- Before using the query in mParticle, test the query outside of mParticle to ensure it returns the data you expect.
- To learn more checkout the Warehouse Sync SQL reference
- Replace
- After updating all necessary values, run COMMAND-S (or CTRL-S) to save your changes.
Step 4: Create your first Warehouse Sync pipeline
Creating a Warehouse Sync pipeline requires completing the following steps:
- Create a partner feed.
- Create a connection.
- Create a data model.
- Create a field transformation
- Create the pipeline.
After configuration, you can monitor the pipeline.
Create the partner feed
First, you must create a data feed by submitting a request to the Feeds API. mParticle uses this feed for rules and connections in your workspace. You must provide a value for module_name that corresponds with the data warehouse you are using.
Valid values for module_name are:
RedshiftBigQuerySnowflakeDatabricks
These values are case sensitive. For example, if you use snowflake instead of Snowflake, you will encounter errors later in your configuration.
- In Postman, ensure the environment drop-down is pointed to the Environment configuration you recently imported.
- Expand the Warehouse Sync Collection and open the Feeds folder.
- Click Create Warehouse Sync Feed.
-
Click the Body tab to see the information you will pass to the API in order to create the feed.
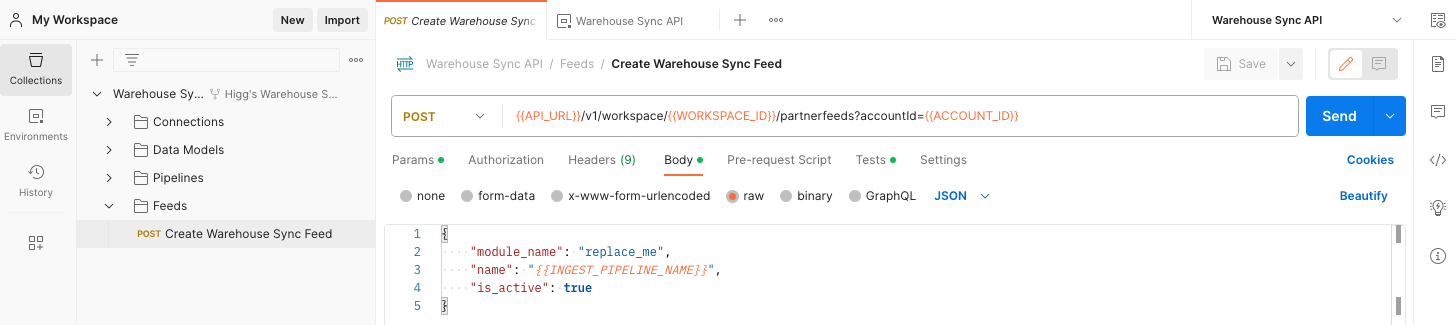
module_namemust be one ofSnowflake,BigQuery, orRedshift
Values surrounded by double braces (for example:
{{WORKSPACE_ID}}) are taken from the variables you updated in previous steps of this tutorial. - Verify all values you changed, and click the blue Send button. mParticle returns a success message with details about your new feed. If the request fails, mParticle returns an error message with additional information.
Create the connection
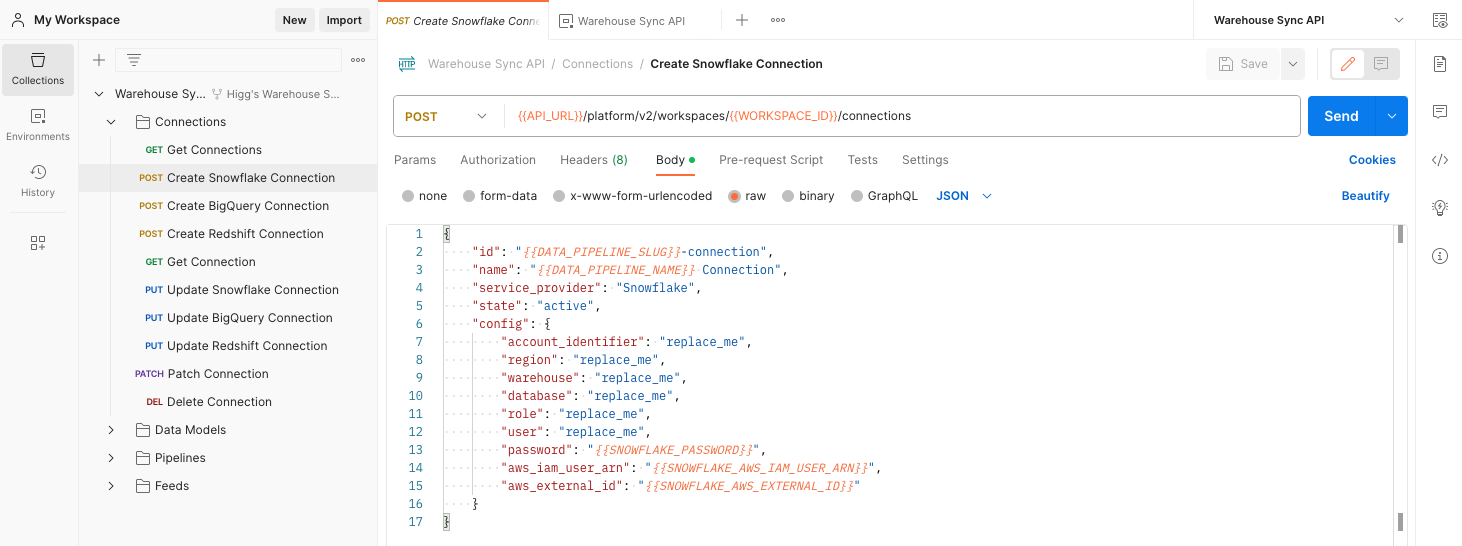
The next step is to create a connection between mParticle and your data warehouse.
- In Postman, ensure the environment drop-down is pointed to the Environment configuration you recently imported.
- Expand the Warehouse Sync Collection and open the Connections folder.
- Click POST Create Snowflake/BigQuery/Redshift Connection, selecting the appropriate endpoint for the data warehouse you are using.
-
Click the Body tab and replace each
"replace_me"placeholder with the correct value for your specific warehouse.The values in
{{Sample Values}}are taken from the environment variables you updated in earlier steps. Make sure these values match the values for your organization’s data warehouse. You may need to work with your database administrator to ensure you have the correct values. -
Verify all values you changed, and click the blue Send button. mParticle returns a success message with details about the configuration you just created. If the request fails, mParticle returns an error message with additional information.
Create the data model
The next step is to create a data model. A data model is a SQL query that mParticle sends to your warehouse specifying exactly what columns, rows, and fields of data you want to ingest through your pipeline.
In the case of pipelines that ingest user profile data, the data model is also responsible for mapping ingested data fields to mParticle user attributes.
Iterator Column Best Practices:
If you are planning to use an incremental pipeline, you will need to include an iterator column in your data model. An iterator column is a timestamp field (such as datetime, date, or Unix timestamp) that tracks which rows have already been processed. This column is essential for reliable incremental updates and should ideally be distinct from your event timestamp field. The iterator column is used by mParticle to determine which rows are new or updated since the last sync.
- Use a dedicated iterator column (such as a system timestamp indicating when a row was inserted or updated) for incremental syncs. This is preferred because the time an event occurred (event timestamp) often differs from when the row was added or updated in your warehouse (iterator/system time).
- Use the iterator column to track which rows have been processed, ensuring reliable incremental updates.
- Use the event timestamp field for filtering in your SQL (for example, in a
WHEREclause) and for mapping to the appropriate mParticle field. - You may use the event timestamp field as the iterator column if convenient, but this is not recommended for most use cases.
- For more details and best practices, see Best Practices for Historical Event Data Ingestion with Warehouse Sync.
To create a data model using the Warehouse Sync API:
- In Postman, expand Warehouse Sync API and click Data Models.
- Click Create Data Model.
-
Select the Body tab and enter your data model.
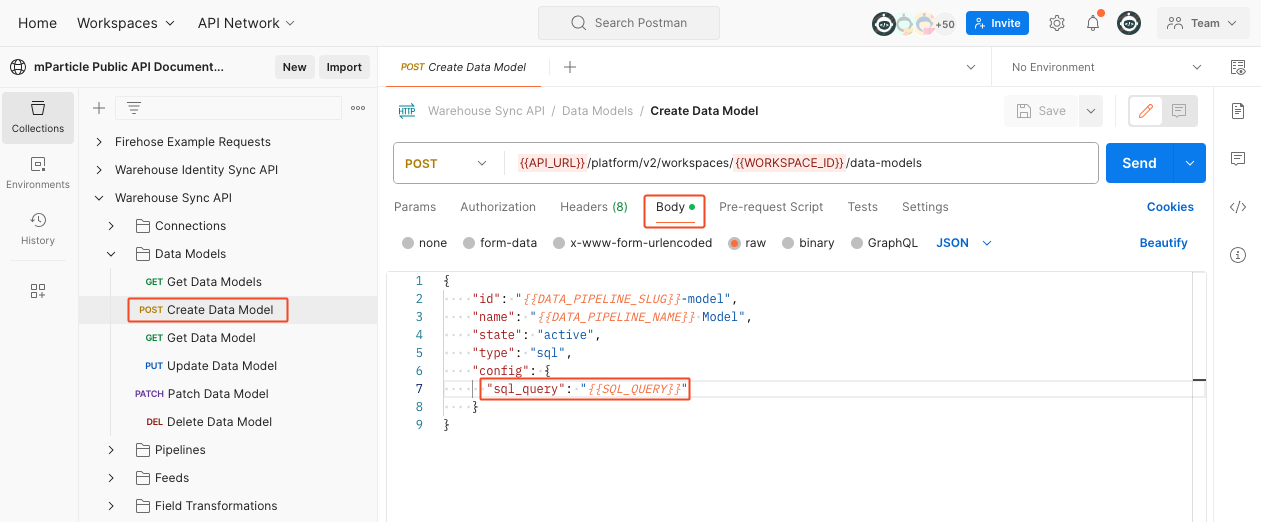
- The values in
{{Sample Values}}are taken from the variables you updated in previous steps. - Once you are confident all values are correct, click the blue Send button. mParticle returns a success message with details about the data model you just created. If the request fails, mParticle returns an error message with additional information.
For more details about using SQL to create a data model, with example queries and best practices, see the Warehouse Sync SQL Reference.
Create the field transformation
You can create a field transformation to specify exactly how fields in your database should map to fields in the mParticle JSON schema.
For detailed instructions on how to create a field transformation, read Event Data Mapping.
To use your field transformation, add the field_transformation_id to the request body of your API call when creating your pipeline in the next step.
Create the pipeline
The final step is to create the pipeline. You pass in the connection and data model configurations previously created along with your sync mode and scheduling settings.
Choosing Full vs Incremental Syncs:
- Full pipelines re-read the entire result set every time they run and are well-suited for small tables or ad-hoc, on-demand replays. They may ingest duplicate data due to deduplication limits for very large datasets. Use SQL WHERE clauses to ensure no overlap in data between runs.
- Incremental pipelines require an iterator column and only fetch rows whose iterator value is greater than the last successful run. The first run backfills everything from the
fromvalue you set; subsequent runs pick up new rows. Leaveuntilblank to let the pipeline continue indefinitely. - A pipeline’s
sync_modecannot be changed after it is created. If you need both full and incremental behavior, you will need to create separate pipelines.
Best Practices for Iterator Fields:
- Choose an iterator column that reliably tracks new or updated rows (e.g., a system-modified timestamp).
- Avoid using event timestamps as iterator columns unless necessary, as these may not reflect when data was actually available for sync.
- You can offset the iterator column by a fixed amount to accommodate late-arriving data. For example, if data typically arrives in your warehouse one day after creation, set the pipeline’s
delayfield to1dto account for this upstream processing time. - For more on batching, backfills, and advanced patterns, see Best Practices for Historical Event Data Ingestion with Warehouse Sync.
- In Postman, expand Warehouse Sync Collection and open the Pipelines folder.
- Click
Create Pipeline. -
Select the Body tab, and update the
sync_modeandschedulesettings as follows:-
For
sync_mode:- Set
typeto eitherincrementalorfull - If you set
typetoincremental, Setiterator_fieldto the name of the column in your sql query mParticle will monitor to track changes that need to be synced -
If you set
typetoincremental, Setiterator_data_typeto the datatype of your iterator- Valid values for Snowflake are:
timestamp_ltz, timestamp_ntz, timestamp_tz, datetime, date, timestamp_unixtime_ms, timestamp_unixtime_s. - Valid values for Google BigQuery are
datetime,date,timestamp,timestamp_unixtime_ms,timestamp_unixtime_s. - Valid values for AWS Redshift are
date,timestamp,timestamptz,timestamp_unixtime_ms,timestamp_unixtime_s. - Valid values for Databricks are
date,timestamp,timestamp_unixtime_ms,timestamp_unixtime_s.
- Valid values for Snowflake are:
- Set
-
-
For
schedule:- Set
typetointerval,once, oron_demand - If you set
typetointerval, setfrequencytohourly,daily,weekly, ormonthly - Set
startto the date-time value you want recurring syncs to begin
- Set
<img src="/images/dwi/api-v2-tutorial/5.png" alt="Postman page showing request results">
The values in `{{Sample Values}}` will be taken from the variables you updated in previous steps. You can optionally update the `environment` variable. It is currently set to target your mParticle development environment, but you can change it to target your production environment.- Set the
field_transformation_idto the ID of a a custom field transformation to map data from your warehouse to specific fields in the mParticle JSON schema. To learn more about custom field transformations and how to create them, see Field Transformations API. - You can associate an optional data plan with your pipeline to help improve the quality of, and grant you more control over, the data imported to mParticle. In the request body of API request, include the body parameters
plan_idandplan_versionand set these to the values of the data plan and version you want to use. You must use a data plan version that is active and exists in the mParticle workspace you are using. - Once you are confident all values are correct, click the blue Send button. If successful, mParticle returns a success message with details about the configuration you just created. If it was not successful, mParticle returns an error message with additional information.
Monitor the pipeline
Once a pipeline has been created, you can monitor its status using the additional requests provided in the Postman collection.
- In Postman, expand the Warehouse Sync Collection and open the Pipelines folder.
- Click
Get Pipeline Report. - Click the blue Send button.
-
mParticle sends a detailed message with the pipeline’s current status. After creating a pipeline, there is an approximate one-minute delay until the pipeline is created in the mParticle backend, so submitting a
Get Pipeline Reportrequest results in aNot Founderror. Try again after several minutes.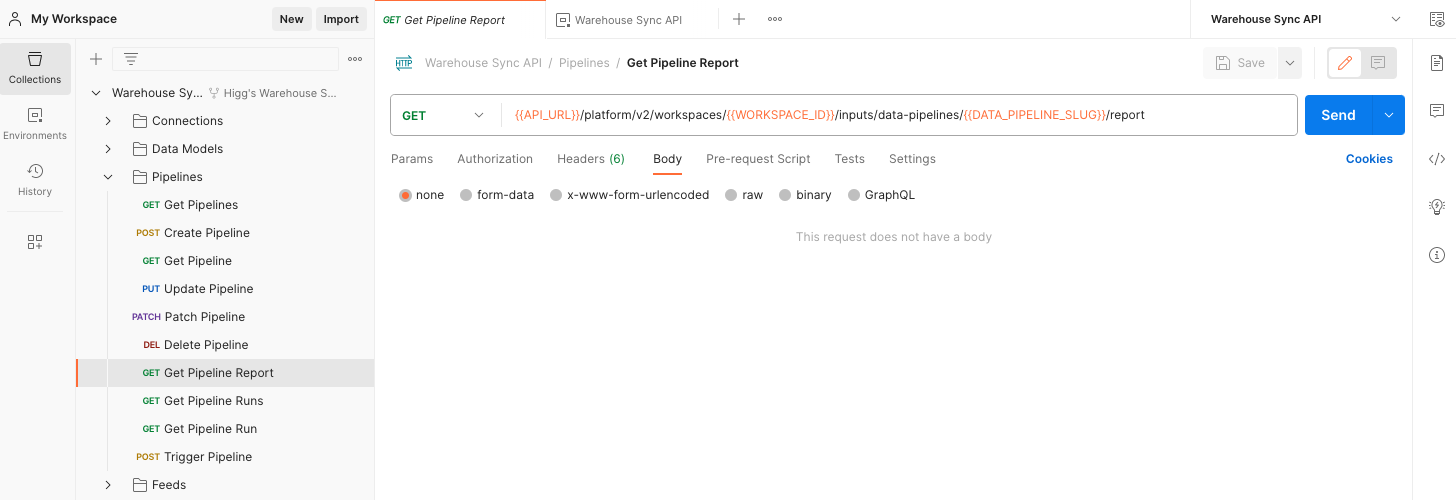
-
While a pipeline is ingesting data, you can monitor it in mParticle as you would with any other input. From mParticle, go to Data Master > Live Stream to inspect the incoming data from Snowflake.
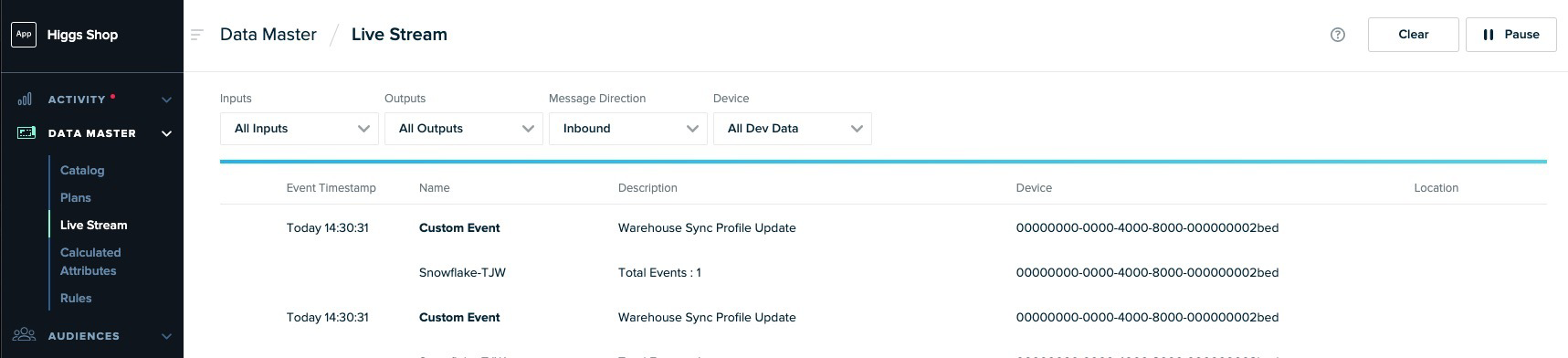
-
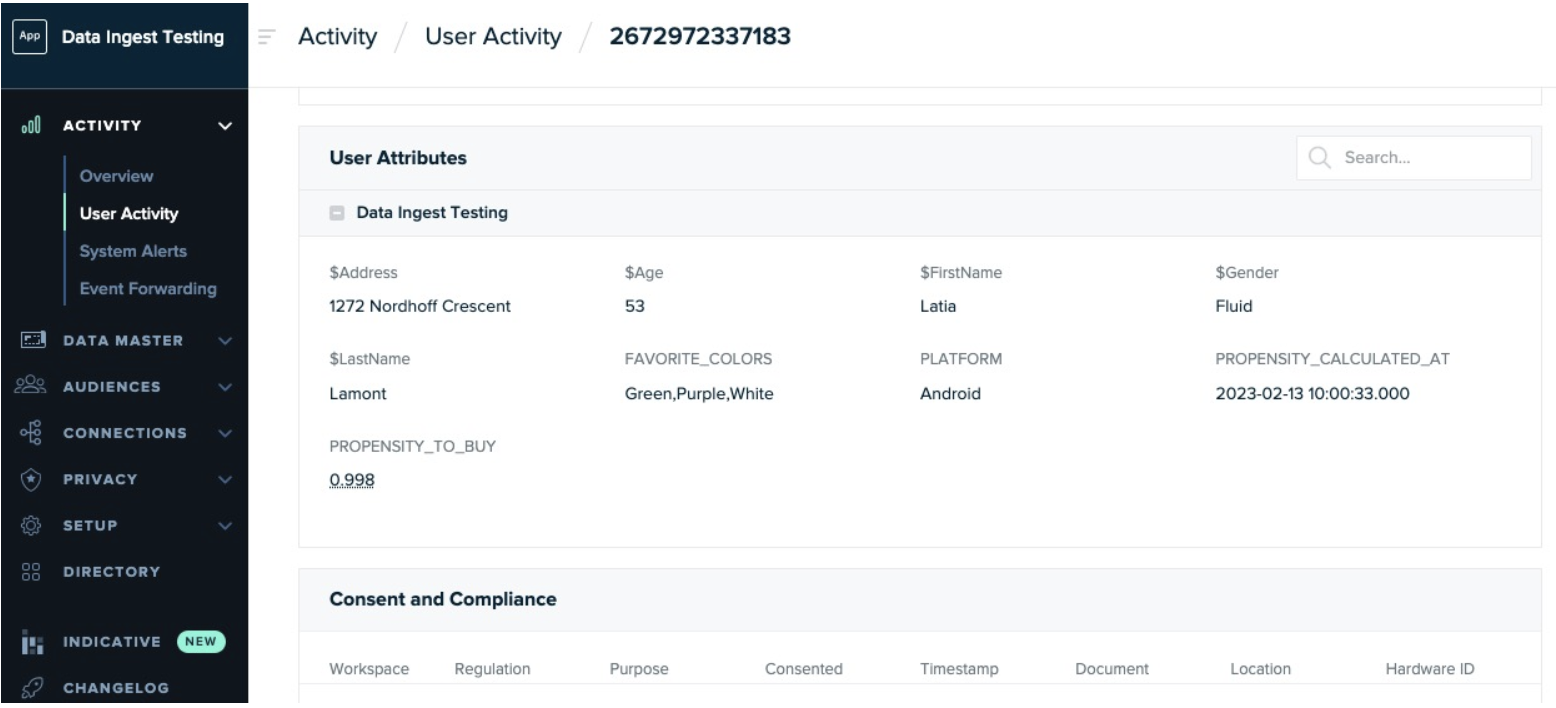
Once the data is ingested, the data points appear on the user’s profile. Go to Activity > User Activity and look up a sample profile. If the attributes do not appear as expected, validate the mapping you provided in the SQL query provided earlier.
Step 5. Activate the data
Now that the data has been loaded into mParticle, it’s time to put it to use by creating an audience using the newly ingested data and sending it to a downstream integration.
Create an audience
Create an audience that uses one of the attributes we ingested as a qualifying criteria for it:
- In the mParticle app, go to Audiences > Standard.
- Click the green New Standard Audience in the upper right corner.
- Give the audience a name.
- Select a date range, or choose “All available data.”
- Select the Warehouse Sync feed you created in mParticle Setup.
-
Add an audience criteria that leverages one of the data points you ingested from your warehouse. In the example below, we only want to consider users who have a propensity-to-buy score that’s greater than 0.7.
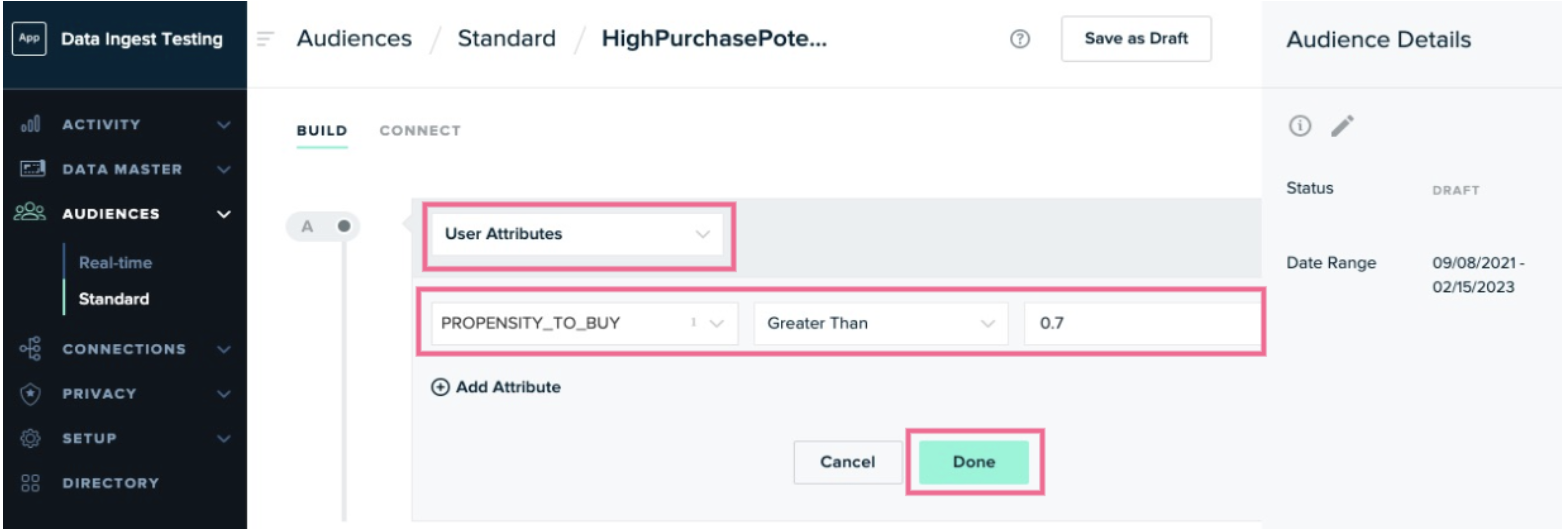
- Add any other criteria you want to be considered. Click Save As Draft when you are done.
- Click Calculate to run the audience calculation.
Connect the audience to an output
In the final step, we will send users who qualified for this audience to Iterable for further targeting. If your organization doesn’t use Iterable, pick a different integration that your organization uses.
After the audience has been fully calculated, connect it to an output:
- If you aren’t still there, go to Audiences > Standard.
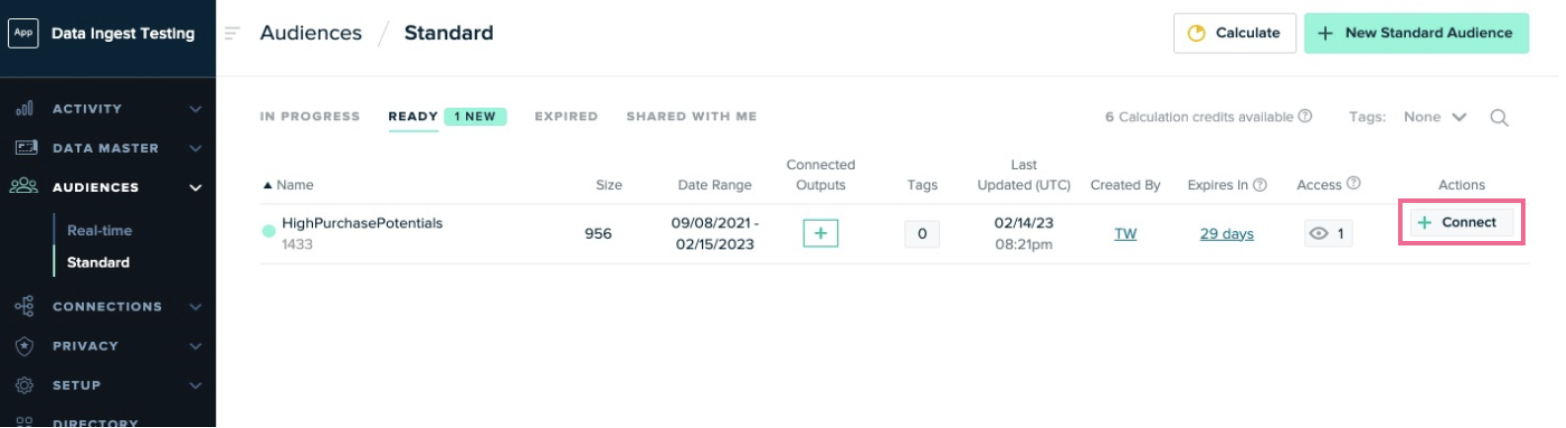
-
In the row for the audience you just created, click the Connect button in the Actions column.
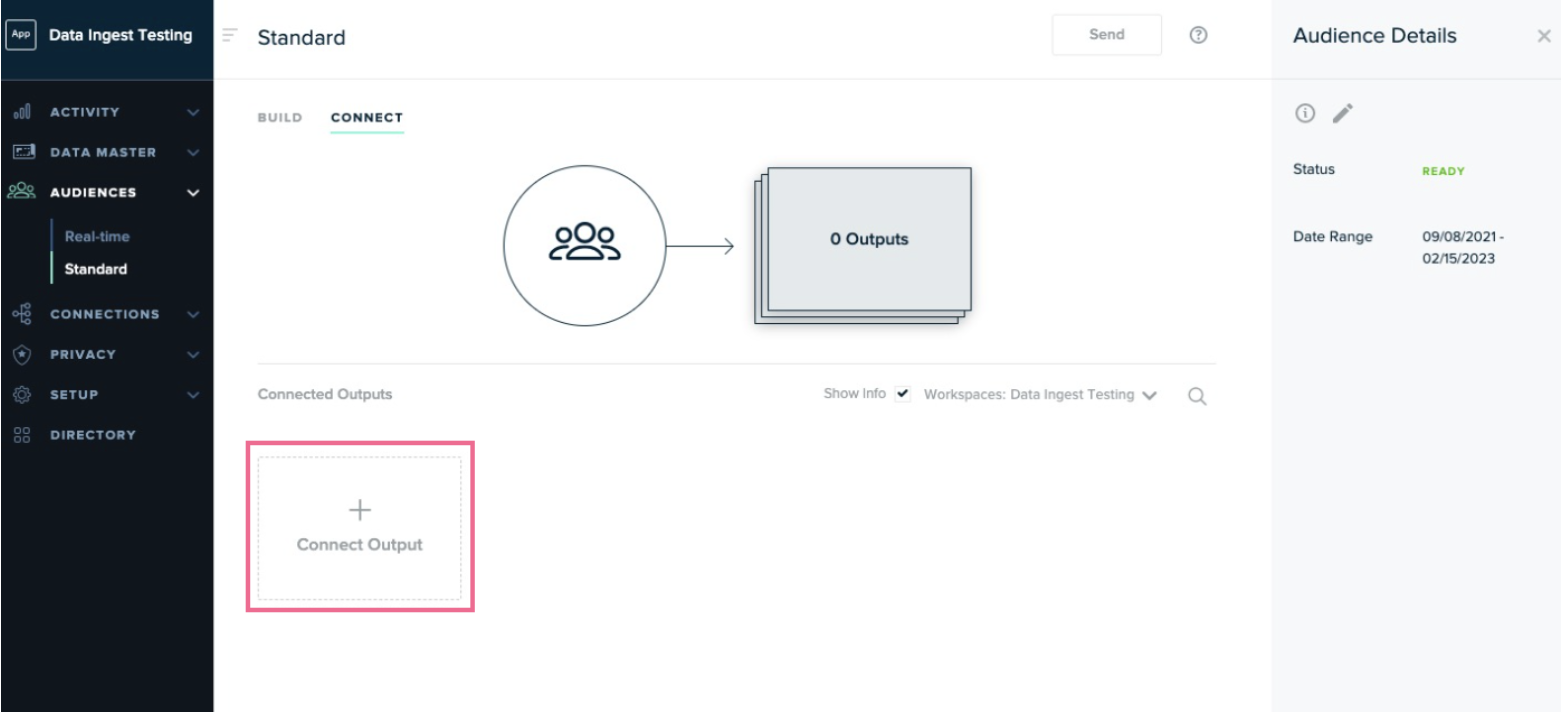
-
Click Connect Output.
- Click the Add Output green button.
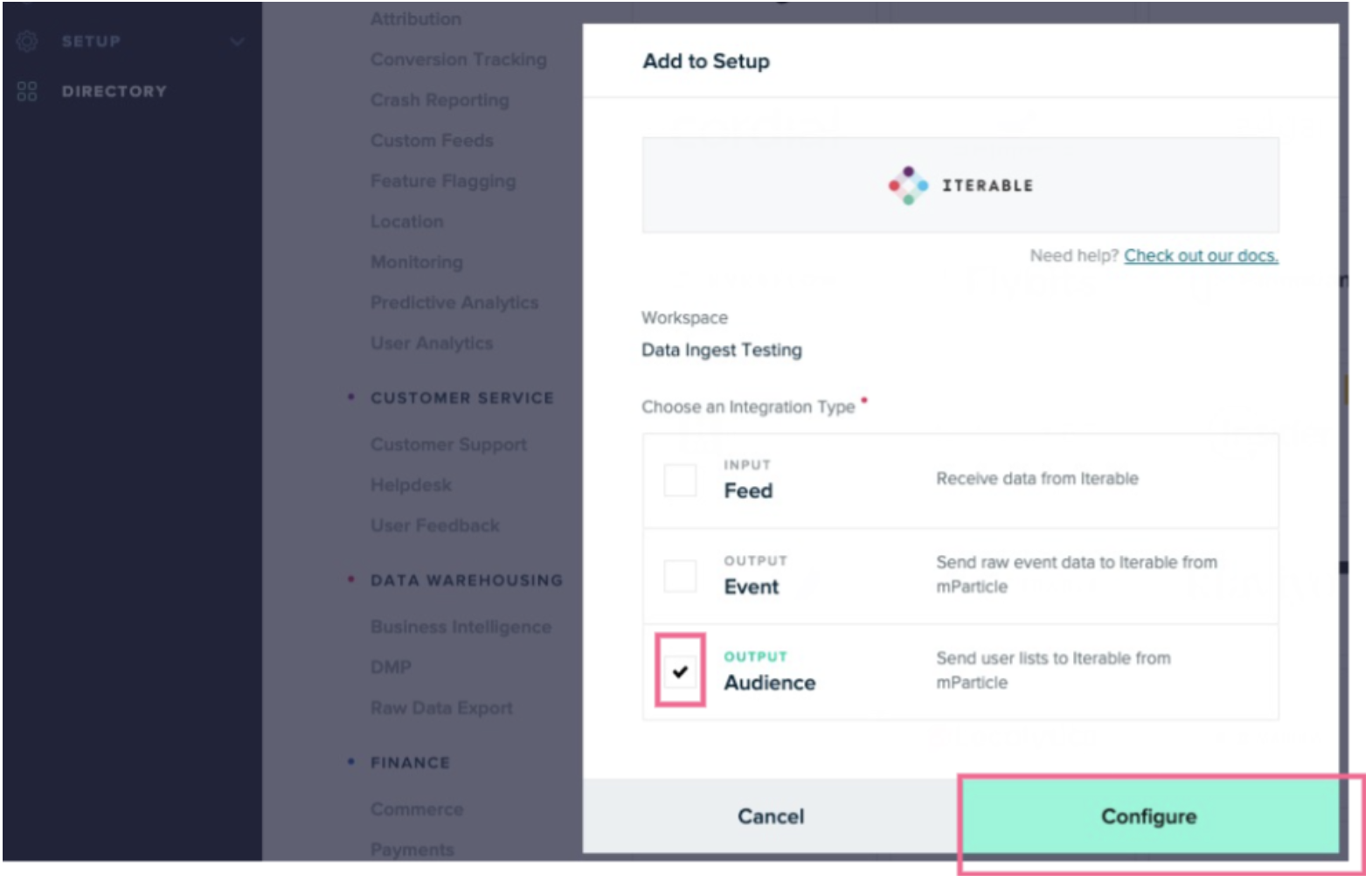
- Click the Iterable tile in the integrations directory, or pick another integration your organization uses if you don’t have Iterable.
-
Select the Audience checkbox and click Configure.
-
Enter a configuration name, your Iterable API key, and the user ID that is used to identify users, and then click Save & Open in Connections.
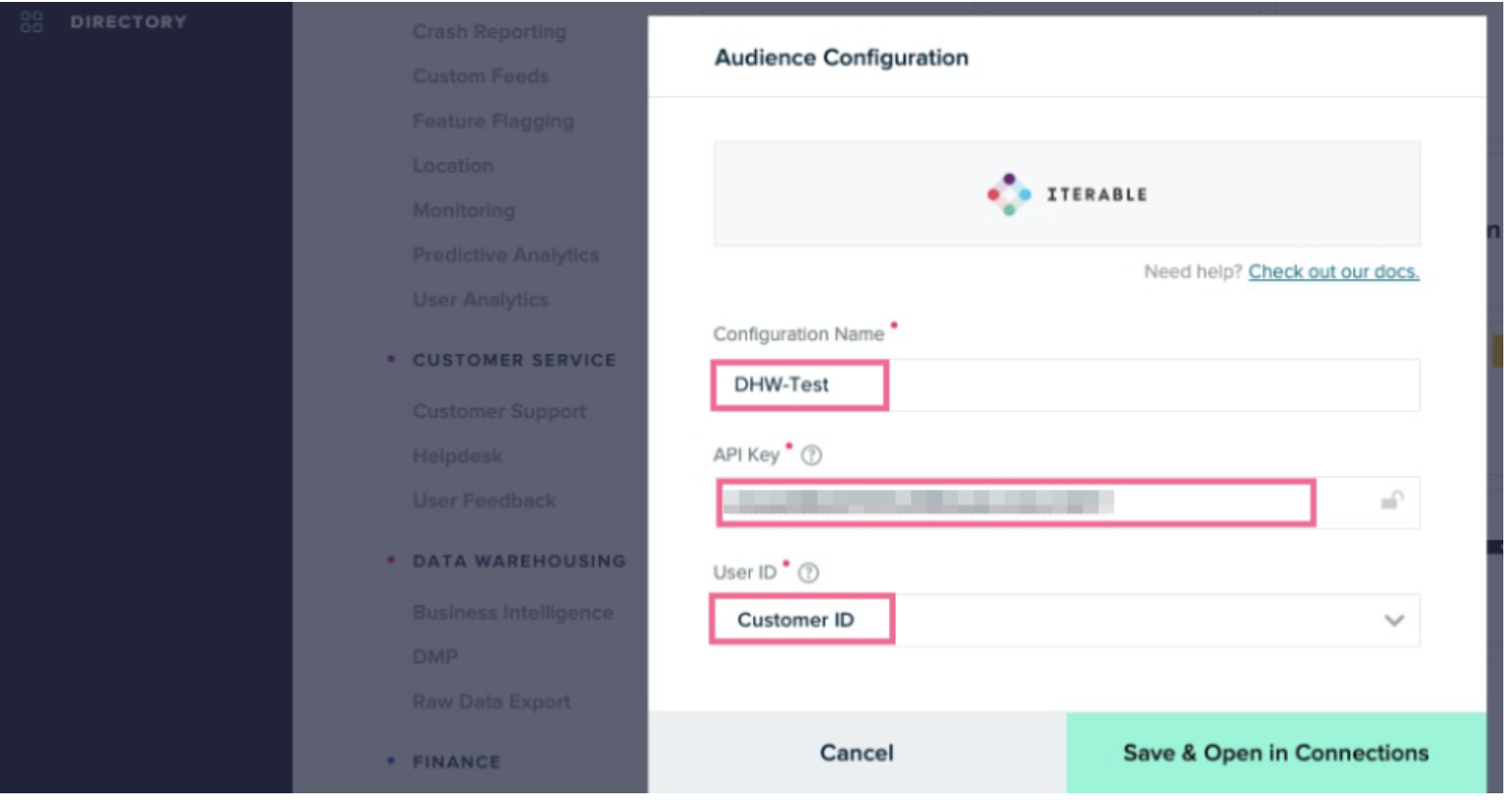
-
Provide the ID of the list in Iterable that the user data should be loaded into, and click Add Connection.
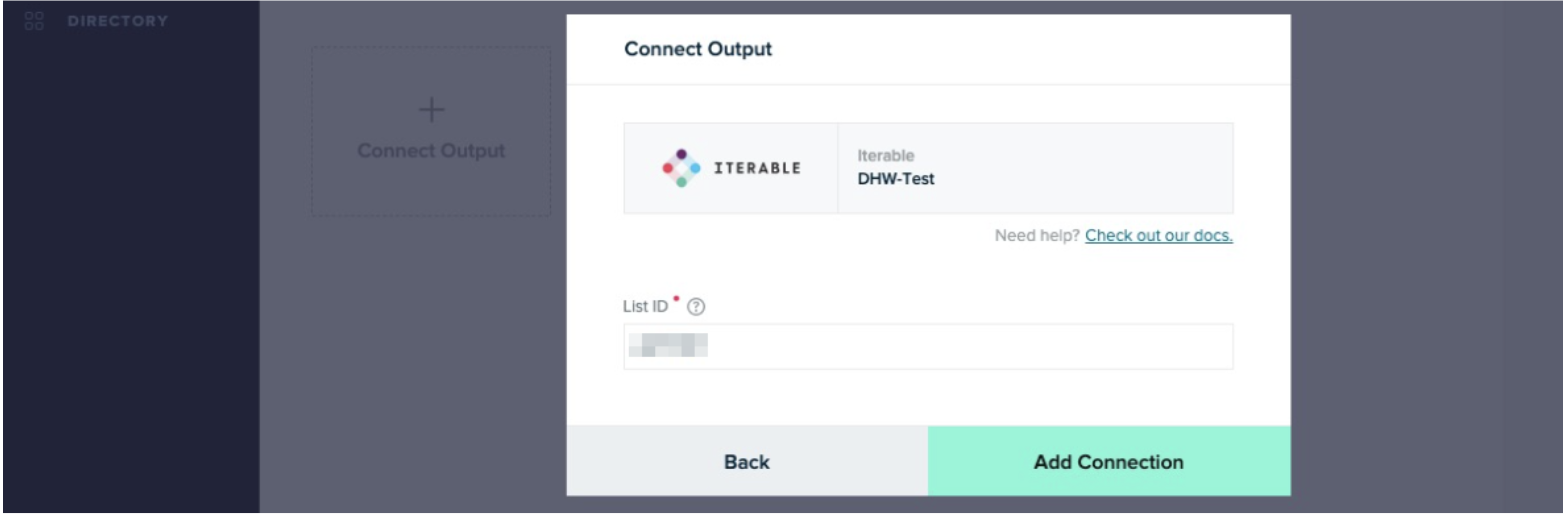
-
Click the Send button to send the audience to Iterable.
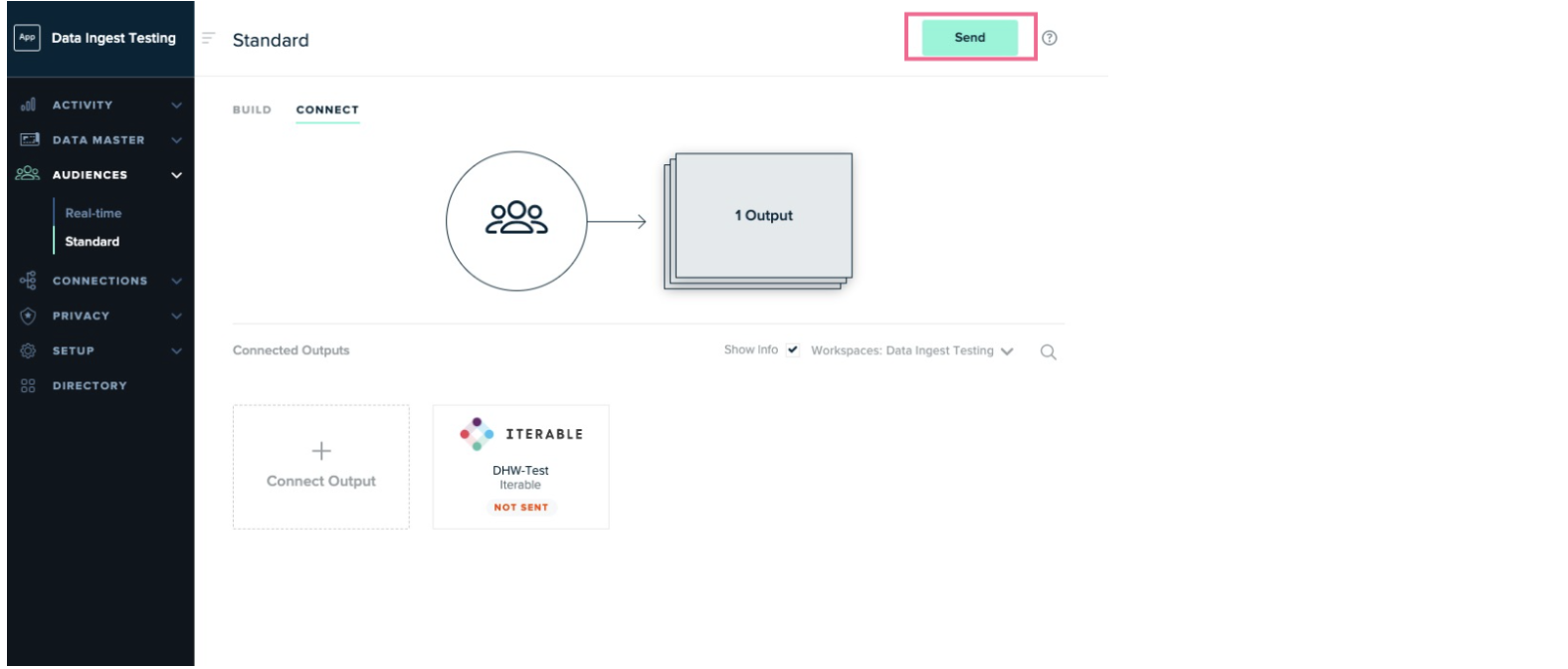
-
Data starts flowing to Iterable.
Now you can open the audience in Iterable.
Was this page helpful?
- Last Updated: March 25, 2026